
Pyspark 데이터 프레임에서 랜덤 샘플링하는 방법을 찾아보다가 세가지 방법이 있길래 정리하려고 한다.
우선, 샘플링하고자 하는 데이터 프레임을 생성했다.
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[1]").appName("regexp_replace").getOrCreate()
address = [("RJFK-SLFKW-DFG1T","M BS", "1"),
("aedw-dg93r-d62g1","W SE", "2"),
("DFGE-FD23k-DA4G1", "M GJ", "3"),
("dssf-dg93r-d62g1","W SE", "4"),
("grdg-dg93r-d62g1","W SE", "5"),
("hrth-dg93r-d62g1","W SE", "6"),
("hjtr-dg93r-d62g1","W SE", "7"),
("rnhe-dg93r-d62g1","W SE", "8"),
("snbf-dg93r-d62g1","W SE", "9"),
("shlr-dg93r-d62g1","W SE", "10"),]
df =spark.createDataFrame(address,["id","demo","visit"])
df.show()
df.printSchema()
#+----------------+----+-----+
#| id|demo|visit|
#+----------------+----+-----+
#|RJFK-SLFKW-DFG1T|M BS| 1|
#|aedw-dg93r-d62g1|W SE| 2|
#|DFGE-FD23k-DA4G1|M GJ| 3|
#|dssf-dg93r-d62g1|W SE| 4|
#|grdg-dg93r-d62g1|W SE| 5|
#|hrth-dg93r-d62g1|W SE| 6|
#|hjtr-dg93r-d62g1|W SE| 7|
#|rnhe-dg93r-d62g1|W SE| 8|
#|snbf-dg93r-d62g1|W SE| 9|
#|shlr-dg93r-d62g1|W SE| 10|
#+----------------+----+-----+
#root
# |-- id: string (nullable = true)
# |-- demo: string (nullable = true)
# |-- visit: string (nullable = true)
1.sample

- withReplacement: 복원 추출 여부, False시 비복원 추출
- fraction: 추출비율, 0 ~1
- seed: 시드지정
추출비율을 0.2로 설정한 결과 10개중 2개의 record가 랜덤으로 샘플링 돼야 하는거 같은데 3개가 나왔다.
sample 함수 자체가 베르누이 분포를 가정으로 랜덤 샘플링 하기 때문에 2개가 나올수도 있고, 안 나올수도 있다.
df.sample(False, 0.2).show()
#+----------------+----+-----+
#| id|demo|visit|
#+----------------+----+-----+
#|DFGE-FD23k-DA4G1|M GJ| 3|
#|grdg-dg93r-d62g1|W SE| 5|
#|shlr-dg93r-d62g1|W SE| 10|
#+----------------+----+-----+
2.sampleBy
sampleBy는 sample과 다르게 col을 지정하고 col value에 따라 층화 랜덤 추출을 한다.

- col: col 명, str
- fraction: dictionary 값으로 {key : 비율지정)
- seed: 시드지정
다음은 2로 나누었을때 나머지인 col에 대한 층화추출 예시이다. 0값에서 20%와 1값에서 60%를 랜덤추출한 결과이다.
df2 = df.select((col("visit") % 2).alias("key"))
df2.show()
#+---+
#|key|
#+---+
#|1.0|
#|0.0|
#|1.0|
#|0.0|
#|1.0|
#|0.0|
#|1.0|
#|0.0|
#|1.0|
#|0.0|
#+---+
df2.sampleBy("key", {0: 0.2, 1:0.6}).show()
#+---+
#|key|
#+---+
#|1.0|
#|1.0|
#|0.0|
#+---+
3.takeSample
takeSample은 위의 sample과는 다르게 두 번째 인자를 지정하여 몇 개를 추출할 것인지 정할 수 있다. 하지만, 결과 값이 RDD가 아닌 리스트나 배열이기 때문에 드라이버 메모리에 주의해야한다. 즉, 크기를 정해놓고 샘플을 추출하고자 한다면 takeSample() 메서드가 적합하지만 큰 데이터에서 샘플링을 하는 경우에는 부적절하다.
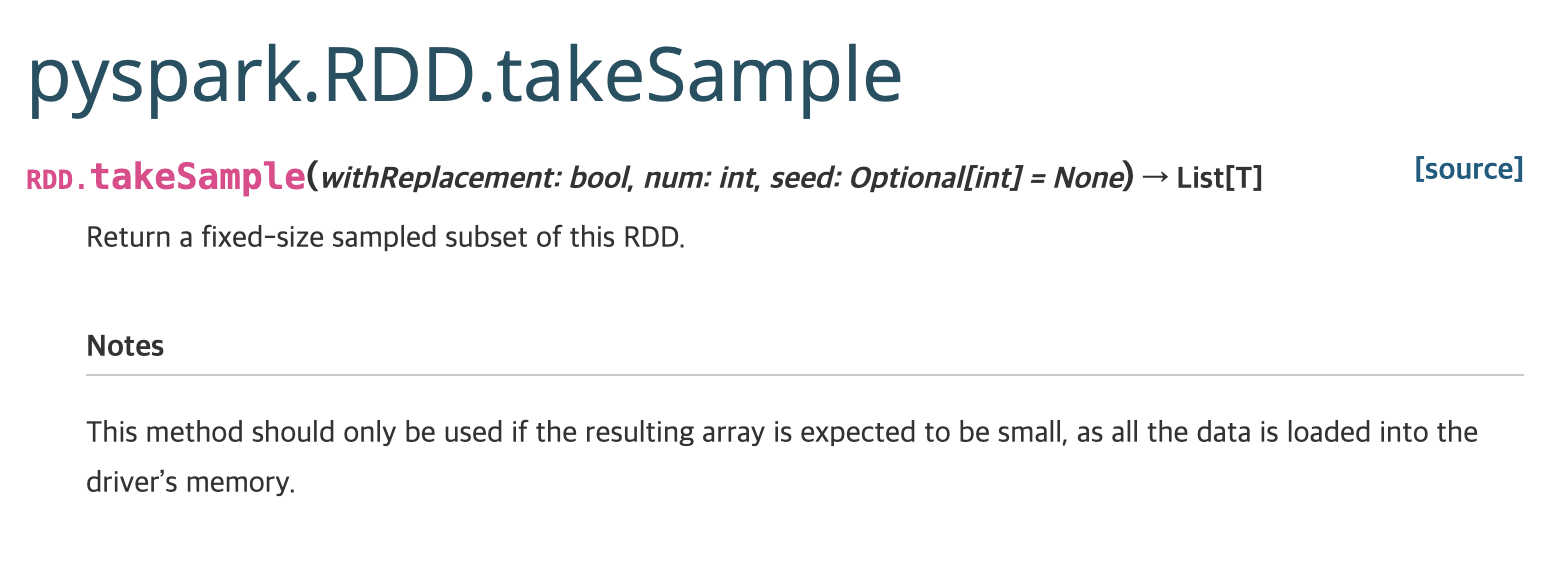
- withReplacement: 복원추출여부, False시 비복원 추출
- num: 추출하고자 하는 샘플갯수
- seed: 시드지정
rdd = df.rdd
result = rdd.takeSample(False, num = 5)
print(result)
#[Row(id='aedw-dg93r-d62g1', demo='W SE', visit='2'),
#Row(id='hjtr-dg93r-d62g1', demo='W SE', visit='7'),
#Row(id='dssf-dg93r-d62g1', demo='W SE', visit='4'),
#Row(id='snbf-dg93r-d62g1', demo='W SE', visit='9'),
#Row(id='RJFK-SLFKW-DFG1T', demo='M BS', visit='1')]
result2 = spark.createDataFrame(result)
result2.show()
#+----------------+----+-----+
#| id|demo|visit|
#+----------------+----+-----+
#|aedw-dg93r-d62g1|W SE| 2|
#|hjtr-dg93r-d62g1|W SE| 7|
#|dssf-dg93r-d62g1|W SE| 4|
#|snbf-dg93r-d62g1|W SE| 9|
#|RJFK-SLFKW-DFG1T|M BS| 1|
#+----------------+----+-----+
Reference
https://sparkbyexamples.com/pyspark/pyspark-sampling-example/
300x250
반응형
'프로그래밍 > PySpark' 카테고리의 다른 글
| [PySpark] 데이터프레임 값을 리스트로 반환하기 (0) | 2023.02.10 |
|---|---|
| [PySpark] 빈 데이터 프레임 생성하고 데이터 집어넣기 (0) | 2023.02.10 |
| [PySpark] SparkConf로 Spark 환경설정 (0) | 2023.02.03 |
| [PySpark] 백분위수(percentile), 사분위수(quantile) (0) | 2023.01.25 |
| [PySpark] regexp_replace 함수 (1) | 2023.01.17 |