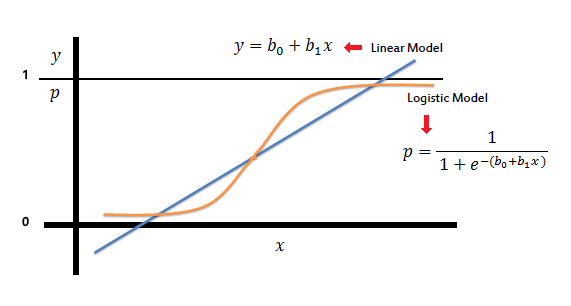
pyspark로 k-means 클러스터링을 하는 code를 정리한다. 우선, pyspark에서 머신러닝 module을 사용하기 위해서는 알고리즘에 사용되는 features의 vectorize 과정이 필요하다. (vector 형태의 column이 ML 알고리즘의 Input으로 들어가게됨) 여기서 pyspark의 vector에 대해 정리해뒀는데 참고! https://sikmulation.tistory.com/45 [PySpark] dense 벡터와 sparse 벡터, UDF로 sparse vector 만들기 1.vector 개념 희소 벡터를 생성하려면 벡터 길이(엄격하게 증가해야 하는 0이 아닌 값과 0이 아닌 값의 인덱스)를 제공해야 합니다. pyspark.mllib.linag.Vecotors 라이브러리는..