
1.단어의 의미를 나타내는 여러가지 방법들
'How do we represent the meaning of word?' 어떻게 단어의 의미를 표현할 수 있을까? 언어학자들이 생각하는 일반적인 단어의 표현방식은 '표시적 의미론'(denotational semantics)을 따르는데 signifier(symbol) <=> signified(idea or thing) 즉, 사전처럼 단어와 해당 단어를 의마하는 바를 매칭 시키는것과 같다. 전통적 방식의 자연어 처리 솔루션으로 wordnet을 고려할 수 있다.
1-1.WordNet & one - hot vector

*NLTK(Natural Language Toolkit) 패키지는 교육용 자연어 처리 파이썬 패키지로 다양한 기능을 포함함.
WordNet은 동의어와 상위어 리스트가 포함된 사전이다. 사전에서 단어는 discrete symboles로 취급하는데 이것은 localist 표현방식을 사용했다는 점이다. 사전관리를 통한 단어의 표현방식에서 더나아가 단어 자체를 one - hot vector 형태로 표현할 수 있다. (= 총 단어의 수만큼의 차원 공간에서 단어 표현이 가능하다.)

이런 표현방식은 굉장히 직관적이지만 전통적인 방식의 한계점이 존재한다.
- 사전관리의 차원 - 신조어 관리, 인력, 시간 투입
- 단어간의 유사성 파악이 어렵다 - one - hot vector의 특성상 단어간 독립적인 vector로 구성되므로 관계(유사도)를 알 수 없다. 두 벡터가 직교(orthogonal) 하다는 의미.
- 차원의 저주 - 계산 복잡도가 굉장히 크다. 예를 들어 100만개의 단어가 있다면 99만 9999개의 0인 sparse vector로 표현된다.
- 주관적인 판단 기준 및 뉘앙스 파악 어려움
1-2.Distributed representation
위의 'Localist 표현 방식'의 문제를 해결하기 위해서 나온 방식이 'Distributed 표현 방식'이다.
*DIstributed 표현 방식은 distributional hypothesis 라는 가정하에서 나옴 - 비슷한 위치에서 자주 등장하는 단어들은 비슷한 의미를 가짐.
one - hot vector로 각 단어의 의미를 표현하는 것이 아닌 하나의 벡터에 단어의 여러 차원에 분산하여 단어의 속성을 나타냄. 즉, dense vector로 단어를 표현. 단어의 의미는 해당 단어 근처에 자주 출현하는 단어에서 얻을 수 있으며 해당 아이디어를 활용해 단어의 의미를 학습하는 대표적인 알고리즘으로 word2vec이 있다.

2.word2vec
2-1.개념
충분한 양의 corpus(말뭉치)를 바탕으로 각 단어를 잘 표현하는 dense vector값을 찾는다. 단어를 표현하는 벡터간의 유사도를 계산해 특정 맥락에서 특정 단어가 나타날 확률값을 계산한다.

위의 예에서 'into'라는 중심단어(center word)가 주어졌을 때 주변 맥락단어(context word)와 유사도 계산을 한다. 즉, 'into' 라는 단어가 주어졌을 때 'banking', 'turning' 등.. 이 나타날 확률을 계산하고 확률값이 최대가 될 때까지 계산을 하게 된다.
$$W_t: 현재위치 t에 있는 단어, \quad W_{t+n},W_{t-n}: 주변단어$$가 주어졌을 때 $$P(W_{t+n}|W+{t}), P(W_{t-n}|W+{t})$$을 최대화 하는 vector를 찾는다. 이 과정을 corpus(말뭉치) 안의 모든 단어에 대해 적용하는 것이 Skip-gram을 활용하여 단어를 임베딩(embedding) 하는 하나의 방법이다.
2-2.L($\theta$), Likelihood
t(=현재위치)에 있는 중심단어에 대한 가능도 함수는 다음과 같다.
$$L(\theta) = \Pi^{T}_{t=1}\Pi_{-m \le j \le m, j \neq 0}P(w_{t+j}|w_{t};\theta)$$
word2vec의 가능도 함수(Likelihood fuction)을 살펴보자. t(=현재 위치)가 1 ~ T 까지 즉, 중심단어 $w_t$이 주어졌을때 문맥단어 $w_{t+j}$가 나오는 확률 $p(w_{t+j}|w_{t};\theta)$을 가능하게 하는 모든 확률곱을 위와 같이 나타낼 수 있다. 따라서, 위 가능도 함수를 최대화(maximize) 하는 $\hat{\theta}$(=MLE; maximize likelihood esimator)를 추정하는 것이 우리의 목적이 된다. (*m: window 크기)
2-3. J($\theta$), Object function(=목적함수, 비용함수, loss함수)
위의 가능도 함수를 최대화 하는 $\theta$를 찾는 문제는 log, 와 '-'부호를 사용하여 변환한 목적함수(=손실함수)를 최소화(minimize)하는 문제랑 동일하다게 된다. 즉, 아래와 같은 목적함수(=negative log likelihood)를 최소화 하는 $\theta$를 추정하면 된다. 위의 가능도 함수를 - 와 log로 변환해 목적함수를 최소화 하는 문제로 바꾼 이유는 log안의 1이하의 작은 확률 값을 크게해 계산을 편리하게 하고 loss값의 분포를 좀 더 regular하게 하기 위함이다.
$$ J(\theta) =-\frac{1}{T}logL(\theta) = -\frac{1}{T}\sum^{T}_{t=1}\sum_{-m \le j \le m}logP(w_{t+j}|w_{t};\theta)$$
2-4.조건부 확률
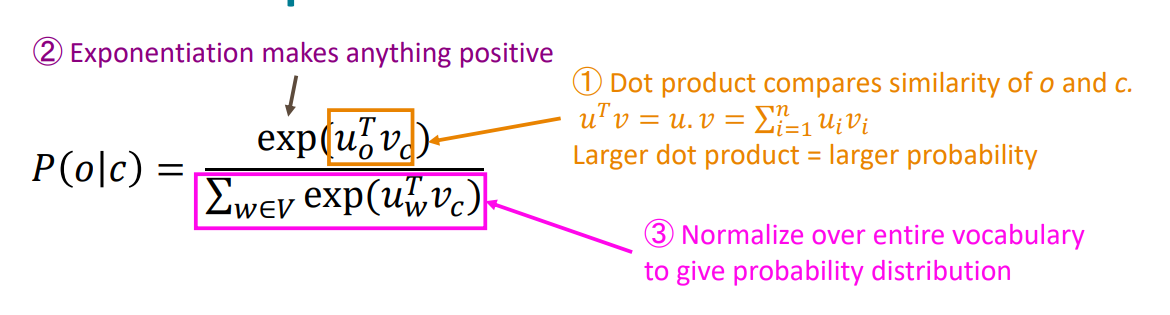
$$ P(o|c) = \frac{exp(u^{T}_{o}v_{c})}{\sum_{w \in V}exp(u^{T}_{w}v_{c})}$$
여기서 c(중심단어, center word), o(주변단어, context word)로 중심단어가 주어졌을때, 주변단어를 예측하는 확률값이다. 각각의 두 단어 벡터의 dot product(내적)을 계산한 후에 더한 값을 분모로 사용하고, 예측하고자 하는 단어의 내적값을 분자에 두면 전체 합이 1인 확률값으로 나타나게 된다. 여기서 내적은 두 단어간의 similarity(유사도)를 나타낸다. 즉, 두 단어간에 유사도가 크면(ex 같이 자주 사용되는 단어 등) 높은 확률값을 가지게 된다.
2-5.최적화
목적함수를 최소화 하는 모델의 파라미터 $\theta$. 즉 단어를 나타내는 두 벡터 $u$, $v$를 찾게 되는데 V개의 단어가 존재하고 우리가 찾는 모수 $\theta$가 d 차원 벡터(d-dimension vector) 일 때, word vector는 2dV 차원을 갖는다.

아래는 목적함수를 중간단어 $u_{o}$와 $v_{c}$에 대해 각각 편 미분한 식으로 중간 단어 $u_{o}$와 예측한 단어와의 차이와 같다. (뒷부분은 $u_{x}$ 예측단어에 대한 기대값) 즉, 실제단어와 예측단어의 기대값의 차이가 작게 예측할 수록 높은 확률값을 가지게 된다. (편미분 도출 방식은 생략했다.)

2-6.배경
주변 문맥 단어에 따라 중간 단어의 확률값을 계산하는 방식을 iteration based methods라고 하는데
Y.Bengio et al.(2003)의 Neral Net Language(NNLM)에서 시작되어,
멀리있는 문맥도 학습가능한 Recurrent Neural Nets 결합한 T.Mikolov et al.(2010) Recurrent Neral Net Language Model(RNNLM) 모델을 발표한다.
이전의 언어모델에 비해 효율, 성능이 좋은 word2vec 모델을 T.Mikolov et al.(2013) 발표하게 된다.
여기서 word2vec의 학습 방식인 CBOW와 Sikp-Gram이 소개되는데 학습하고자 하는 중간단어(ceter word)를 Input, Output으로 두느냐에 따라 나뉜다.
- Continuous Bag of Word(CBOW): 중간 단어가 주어지면 문맥을 추정하는 방식.
- Skip-Gram: 주변단어가 주어지면 중간단어를 추정하는 방식.
여전히 단어수가 증가하면 학습하고자 하는 모델의 파라미터 모수의 차원이 증가해 계산이 복잡해 지는 문제가 있다. 이를 해결하기 위한 방법은 다음과 같다.
- Negative Sampling: 일부 몇개의 단어만 랜덤하게 선택해 학습하는 방법
- Hierachical Softmax: 모든 단어를 고려하되, binary tree를 이용하여 출력층 softmax함수 계산 최소화
reference
https://arxiv.org/abs/1310.4546 - word2vec(skip gram) 후속 논문
skip-gram 구조에 대한 세가지 성능개선 방법인 Negative-sampling, Sub-sampling, Phrase learning 을 제안.
Distributed Representations of Words and Phrases and their Compositionality
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extens
arxiv.org
https://arxiv.org/abs/1301.3781 - word2vec
Efficient Estimation of Word Representations in Vector Space
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best per
arxiv.org
https://youtube.com/playlist?list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ&si=EuDpdGb-CfHjv6af
Stanford CS224N: Natural Language Processing with Deep Learning | Winter 2021
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/ai
www.youtube.com
'Data Science > NLP' 카테고리의 다른 글
| [CS224n] Natural Language Processing with Deep Learning (0) | 2023.10.31 |
|---|