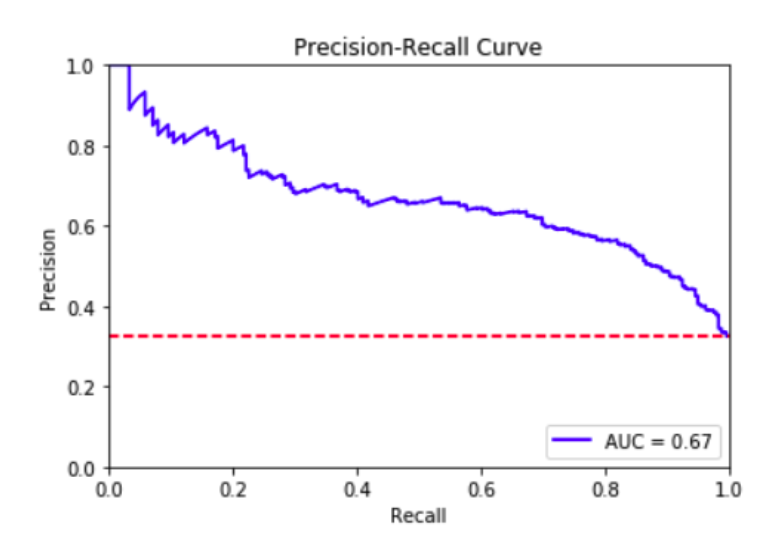
item 우선, 회사에서 데이터 모델링 작업을 하다가 라벨이 심각하게 불균등하고, 게다가 데이터 정보량도 거의 없어 모델링이 필요한가? rule 기반으로 분류 작업을 하면 안될까??? 라는 고민을 하다가 현재 데이터에서 주성분 몇개 빼고 정보량이 없는 상태에서 모델간의 성능 비교를 해보자는 취지로 진행하였다. 그냥 주성분 전부 다써서 기본 로지스틱 모델만 돌려도 성능이 꽤나오는 깔끔한 데이터니 해보실분들은 따로 해보길 권한다. 1. ML용 Input 데이터 구성 우선, Pyspark ML을 이용하기 위해서는 vectorassembler을 이용해 머신러닝 알고리즘용 featurevector를 구성한다. feature가 dense vector 또는 sparse vector로 구성되는데 리소스에 따라 효율이 ..