https://sikmulation.tistory.com/51
[PySpark] 5폴드 교차검증(5-fold crossvalidation) 과 모델선택
1.교차검증과 모델선택 ML 알고리즘 마다 조절해야할 하이퍼 파라미터 옵션이 존재하는데 이를 조정하면서 학습데이터에서 과소적합, 과대적합을 방지 할 수 있다. 그 중 교차검증 방법론은 연
sikmulation.tistory.com
우선, 여기서 교차 검증시 평가함수로 PySpark 함수 BinaryClassificationEvaluator 를 사용했다. 해당 함수는 2개의 metric을 지원하는데
"areaUnderPR", "areaUnderROC" 이다. 그럼 이 두개는 언제 어떨때 쓰는게 좋을까?
1.PR curve(precision - recall)
0부터 1사이의 모든 임계값에 따라 x축: 재현율(Recall), y축: 정밀도(Precision). 정밀도와 재현율 모두 높을수록(오른쪽 위) 좋은 성능의 모델이라고 판단.
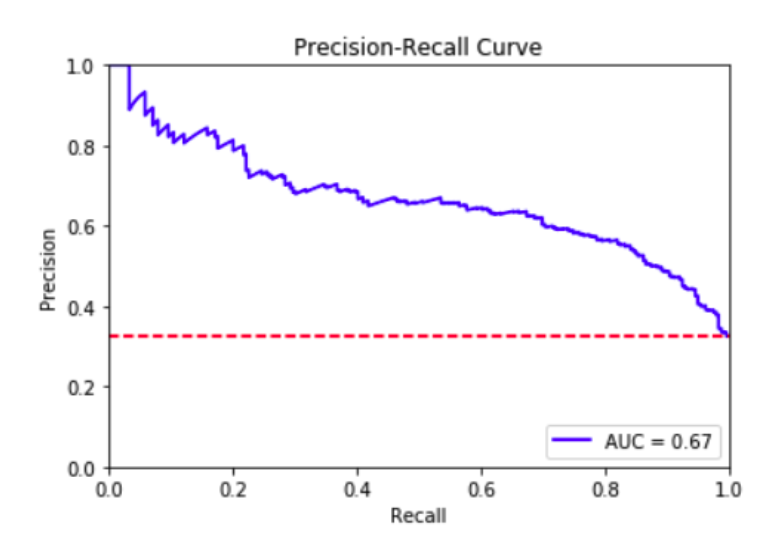
2.ROC curve(Receiver operating characteristic)
0부터 1사이의 모든 임계값에 따라 x축을 FPR(= 1 - 특이도), y축을 TPR(=재현율, 민감도). 즉, FPR이 적고 재현율이 높을수록(왼쪽 위) 좋은 성능의 모델이라고 판단.
이 그래프 눈으로 확인하기 어려워 AUC(Area Under Curve) 개념. 파란 곡선 아래 면적을 구해 넓은 면적을 가진 분류 모형을 더 성능이 좋은 모델이라고 판단할 수 있음.

3.결론
현재 데이터는 라벨이 불균등한 데이터이고 2종 오류의 비용이 1종오류에 비해 크다고 정의했다.(양성 클래스를 탐지하는게 더 중요, ex 암 환자 판별 모델, 캠페인 대상 예측 등)
따라서, TN(실제 음성을 음성으로 판단하는 경우)는 PR curve에 관여하지 않기 때문에 해당 모델의 검증 metric으로 사용(= 양성을 판단하는 것에 더 집중을 하겠다는 의미)
*참고사항1: ROC curve AUC 사용하는 경우
- 데이터 라벨이 균형인 경우
- 양성과 음성 오류에 대한 비용이 비슷한 경우(ex 개, 고양이 분류 등) 적합하다.
- 왜냐하면, TPR과 FPR은 데이터 불균형에 영향을 받지 않는 지표임(PR curve의 precision은 데이터 불균형에 영향을 받는 지표임)
*참고사항2: 성능지표
- 재현율(Recall), TPR: 실제 양성을 양성으로 잘 예측한 비율, TP/(TP + FN)
- TNR(True Negative Rate, 특이도): 실제 음성을 음성으로 잘 예측한 비율, TN/(TN+FP)
- FPR(False Positive Rate, 1-특이도): 실제 음성을 양성으로 잘 못 예측, FP/(TN + FP)
https://sikmulation.tistory.com/36
[머신러닝] 분류모델 성능지표 - 혼동행렬, AUC-ROC 커브, Lift/gain 차트
[분류 모델 성능지표] 목적: 라벨이 있는 경우 이진 분류 모델의 성능지표에 대해 정리한다. 1.혼동행렬(confusion matrix), 2.AUC-ROC curve 3.lift chart, gain chart 1. 혼동행렬(confusion matrix) predicted Positive Negati
sikmulation.tistory.com
'Data Science > 머신러닝' 카테고리의 다른 글
| 엘라스틱 넷 패널티를 활용한 서포트 벡터 머신의 변수선택법 (0) | 2023.07.10 |
|---|---|
| [PySpark] 신용카드 사기거래 탐지 모델링(3) - 기본모델링 (0) | 2023.06.27 |
| [PySpark] 5폴드 교차검증(5-fold crossvalidation) 과 모델선택 (0) | 2023.06.27 |
| 오버피팅(overfitting)과 언더피팅(underfitting)이 뭐길래? (0) | 2023.06.27 |
| [PySpark] 신용카드 사기거래 탐지 모델링(2) - 성능지표정의 (0) | 2023.06.22 |