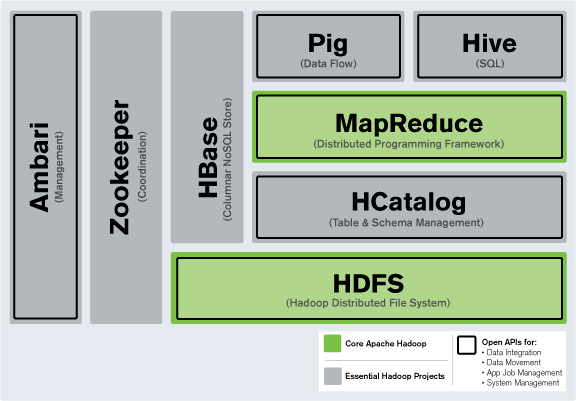
하둡 Hdfs 상에 데이터를 저장하고 PySpark로 분석하면서 정확한 시스템 용어나 개념에 대해서 정리해야지 말만하다가 이제라도 공부하고 정리하려고 한다. 다는 모르더라도 기본적인 것은 알고쓰자! 1.하둡(Hdoop)이란 - HDFS, MapReduce? 하둡은 대규모 데이터를 저장하고 처리하는데 사용되는 오픈소스 분산 컴퓨팅 프레임 웤이다. 아파치 소프트웨어 재단에서 개발하고 관리하며, 대용량(large-scalable) 데이터를 여러 대의 컴퓨터 클러스터에서 처리할 수 있도록 설계되어 있다. 여기서 우리가 알고 가야할 핵심적인 개념을 뽑자면 hdfs와 mapreduce이다. Hadoop 분산 파일 시스템(Hadoop Distributed File System, HDFS) HDFS는 대용량 데이터를 ..