
5-1.워크플로우 관리
<[기초지식] 워크플로 관리>
- 정해진 업무를 원활하게 진행하기 위한 구조
- 워크플로 관리도구
- 정기적으로 태스크 실행
- 비정상적인 상태 감지후 해결
- ex) Airflow, azkaban, Digdag, Luigi, Oozie
- 워크플로 관리도구와 태스크
- 정해진 개별 반복 처리를 태스크(Task)라고 함
- 도구를 사용하는 이유는 태스크 실행의 실패 때문
- 태스크 수 증가로 재실행이 어려워 도구를 활용함
- 워크플로 관리 도구의 기능
- 정기적인 스케쥴로 태스크 실행후 통지
- 태스크간 의존 관계를 정하구 정해진 순서대로 실행
- 태스크 실행결과 보관, 오류 발생시 재실행
- 워크플로 관리 도구의 종류
- 선언 형과 스크립트 형
- 선언형(declarative)
- XML, YAML 등의 서식으로 워크플로 기술
- 미리 제공된 기능만 이용가능하지만 최소한의 기술로 태스크 정의 가능
- 누가 작성하더라도 동일한 워크플로가 돼 유지보수성 높아짐
- 동일 쿼리를 파라미터를 수정해서 여러 번 실행하거나 단순 반복적으로 워크플로 자동생성하는 경우에 사용
- 스크립트형(scripting)
- 태스크의 정의를 프로그래밍할 수 있어 유연성
- 데이터 처리를 태스크 안에서 실행하는것도 가능
- 선언형(declarative)
- 선언 형과 스크립트 형
# Airflow에 의한 워크플로 정의
# 셀 스크립트의 템플릿 정의
SCRIPT = '''
aws s3 cp --recursive s3://example/logs/{{ ds }}/ .
# 셀 스크립트를 실행하는 태스크 등록
task = BashOperator(task_id = 'data_transfer', bash_command = SCRIPT)<오류로 부터 복구방법 먼저 생각하기>
- 복구와 플로우 재실행
- 통신오류와 같이 몇 차례 반복하면 성공하는 오류
- 기다리면 대처 가능
- 인증오류와 같이 몇 차례 반복해도 실패하는 오류
- 수동으로 대처
- 실패한 태스크는 모두 기록하여 나중에 재실행할 수 있도록 해야함
- 일련의 태스크는 플로우(Flow)
- 각 플로우에는 실행 시에 고정 파라미터 부여
- 일별 배치라면 특정 날짜가 파라미터
- 동일 플로우에 동일 파라미터를 부여하면 완전히 동일한 태스크가 실행 되도록 함
- 나중에 실패하더라도 재실행 가능함
- 워크플로 관리 도구에서는 실패한 플로우 선택해서 재실행만으로 복구 가능
- 되도록 태스크를 작게 유지
- 통신오류와 같이 몇 차례 반복하면 성공하는 오류
- 재시도
- 여러번 발생하는 오류를 재시도(Retry) 자동화하여 수작업 없이 복구
- 재시도 간격을 5분이나 10분 정도로 두기
- 재시도 횟수 설정 주의
- 적으면 장애가 복구 되기전에 재시도 종료
- 많으면 실패하지 않은것처럼 되기 때문에 모르고 넘어갈 수 있음
- 오류의 원인을 그때마다 조사해 일어나지 않도록 대책 마련하는게 가장 좋은 해결책
- 백필(backfill)
- 플로우 전체를 처음부터 다시 실행
- 파라미터에 포함된 일시를 순서대로 바꿔가면서 일정 기간의 플로우를 연속해서 실행
- 대규모 백필 실행시 자동적인 재시도는 무효로 하고 오류는 모두 통지하는 편이 좋음
<멱등한 조작으로 태스크 기술하기>
- 각 태스크는 원칙적으로 마지막까지 성공하거나, 실패하면 존재하지 않음을 전제로 해야함
- 원자성 조작(atomic operation)
- INSERT 문 2회 호출하는 태스크, 첫 번째 INSERT 종료한 상황에 오류발생시 태스크 재실행하면 데이터 중복 발생
- 각 태스크가 시스템에 변경을 가하는 것을 한 번만 하도록
- 트랜잭션 처리에 대응한 DB라면 여러번의 쓰기를 한 번의 트랜잭션으로 실행
- 아니라면 쓰기가 필요한 수만큼 태스크 나눔
- 원자성 조작에서의 문제
- 태스크 구현상의 버그로 인해 원자성 조작 직후에 문제 발생하면 원자성 조작 자체는 성공하고 있음에도 워크플로 관리 도구는 오류를 여기는 경우가 있음
- 멱등한 조작(idempotent operation)
- 동일한 태스크를 여러번 실행해도 동일한 결과
- SQL, 테이블 삭제후 다시 만들기
- 원칙적으로 항상 데이터를 덮어 써야함, 각 태스크는 추가(append) or 치환(replace)
# t1 테이블 있으면 삭제
DROP TABLE IF EXISTS "tl";
# t1 테이블 작성
CREATE TABLE "t1" (...);
# t1 테이블 쓴다
INSERT INTO "t1" ...;- 멱등한 추가
- 테이블 파티셔닝
- 파티션 단위로 치환하면 멱등하게 테이블 유지 가능함
- 원자성을 지닌 추가
- 복잡한 플로우에서 하나의 테이블에 몇 번이고 데이터 써 넣음
- 추가 반복이 아니라 중간 테이블을 만들어 처리 후, 마지막에 목적 테이블에 한 번에 추가하는 것이 안전
- 문제 발생시 중간테이블만 삭제하고 재실행 가능
- 재실행의 안전성을 높이기 위해서는 각 플로우가 전체로서 멱등하게 되도록 구현
# 중간테이블 작성(치환)
DROP TABLE IF EXISTS "t1";
CREATE TABLE "t1" (...);
INSERT INTO "t1" ...;
INSERT<태스크 큐 - 자원의 소비량 컨트롤>
- 예시) 2메가바이트의 압축이 안 된 텍스트 파일 1만개 = 20기가바이트
- 하나의 파일을 압축해서 전송하는데 5초 걸리면 단순히 1만번 반복시 약 14시간
- 각 태스크는 파일 서버로부터 파일을 추출하여 압축하고 분산 스토리지로 전송, 태스크는 셸 스크립트화하여 워크플로 관리 도구 안에서 호출
- 대량의 태스크를 동시 실행시 서버 과부하가 걸리므로 제한 필요, 잡 큐(job queue), 태스크 큐(task queue)
- 모든 태스크는 큐에 저장되고 일정 수의 워커 프로세스가 순서대로 꺼내면서 병렬화
- 8개가 병렬로 태스크 실행
- 병목 현상의 해소
- 실제로 8코어 서버에 8개의 워커는 너무 부족, 각 태스크는 CPU 뿐만 아니라 디스크 I/O, 네트워크 I/O 소비
- 워커의 수를 늘리면 좀 더 실행 속도를 높일 수 있으나 너무 증가시키면 어디선가 병목 현상이 발생해 성능 향상이 한계점에 도달해 오류 발생
- 서버의 내부적 요인(증상 - 대책)
- CPU 사용률 100% - CPU 코어 수 늘림, 서버 증설
- 메모리 부족 - 메모리 증설, 스왑 디스크 추가, 태스크 작게 분할
- 디스크 넘침 - 각 태스크가 임시 파일을 삭제하고 있는지 확인, 디스크를 증설
- 디스크 I/O 한계 - SSD 등의 고속 디스크 사용, 여러 디스크로 분산
- 네트워크 대역의 한계 - 고속 네트워크 사용, 데이터 압축률을 높임
- 통신 오류나 타임 아웃 - 시스템 상의 한계 가능성, 서버 분리
- 서버의 외부적 요인
- 파일 복사에서 오류 발생시 파일서버의 성능 한계, 워커를 늘리는건 역효과
- 분산 스토리지로 쓰기 빈도 높아 오류발생시 쓰기 빈도를 줄여야함
- 태스크 수의 적정화
- 태스크에는 날짜와 시간이 파라미터로 건네짐
- 작은 파일을 모아서 하나의 파일로 하거나, 여러 파일을 한 번에 업로드
- 그러한 태스크를 좀 더 많은 워커로 동시에 실행해 처리 효율 최대화
- 최적화 프로세스는 Hadoop과 같은 분산 시스템에서도 동일함
5-2.배치 형의 데이터 플로우
<MapReduce의 시대는 끝났다>
- 데이터 플로우: 다단계의 데이터 퍼리를 그대로 분산 시스템의 내부에서 실행
- MapReduce의 구조
- MapReduce 대체
- 구글 - MillWheel
- Hadoop - Tez
- Spark
- MapReduce 대체
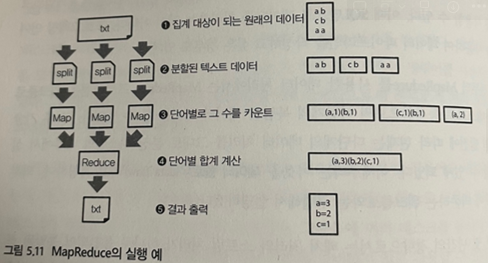
- 3: 분할된 데이터를 처리하는 첫 단계를 ‘Map’
- 4: 그 결과를 모아서 집계하는 두 번째 단계를 ‘Reduce’
- 3,4를 반복하면서 목적하는 결과를 얻을 때까지 계속해서 데이터를 변환해 나가는 구조
- 복잡한 데이터 처리에서는 Map, Reduce 여러번 반복해야 하므로 대기시간 길어짐
- 애드 혹 데이터 분석에서 요구되는 간단한 집계는 MapReduce로 실현하는 것이 어려움
<MapReduce를 대신할 새로운 프레임워크 - DAG>
- DAG(directed actclic graph, 방향성 비순환 그래프)
- 노드와 노드가 화살표로 연결(방향성)
- 화살표를 따라가도 동일 노드로 되돌아 오지 않음(비순환)
- 기존의 MapReduce도 Map과 Reduce의 두 종류의 노드로 이루어진 간단한 DAG, 그러나 하나의 노드 처리가 안끝나면 다음으로 진행 x
- DAG를 구성하는 각 노드가 모두 동시 병행으로 실행, MapReduce에 존재했던 대기 시간을 없앰

# 1: 파일로부터 데이터를 읽어 들인다.
lines = sc.textFile("sample.txt")
# 2: 파일의 각 행을 단어로 분해
words = lines.flatMap(lambda line: line.split())
# 3,4,5: 단어마다의 카운터를 파일에 출력
words.map(lambda word: (word, 1))\
.reduceByKey(lambda a, b: a + b)\
.saveAsTextFile("word_counts") # 실행 개시- DAG에 의한 프로그래밍 특징은 ‘지연평가(lazy evaluation)’
- 먼저 데이터 파이프라인 전체를 DAG로 조립하고 실행에 옮김, 내부 스케줄러가 분산 시스템에 효과적인 실행 계획을 세워주는게 데이터 플로우의 장점
<데이터 플로우와 워크플로를 조합하기>
- 데이터를 읽어들이는 플로우
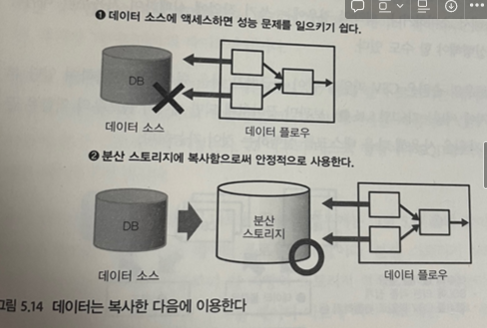
- 데이터 성능적으로 안정된 분산 스토리지에 복사하여 사용, 외부 데이터 소스애 여러 번 접속하면 성능 문제 발생
- 외부의 데이터 소스에서 데이터 읽어 들일 때는 벌크 형의 전송 도구로 태스크를 구현
- 데이터 복사만 와료되면 데이터 플로우 전문 분야, 텍스트 데이터 가공, 열 지향 스토리지로 변환 등 부하가 큰 처리는 데이터 플로우로서 실행

- 데이터를 써서 내보내는 플로우
- 데이터 집계 결과를 외부 시스템에 써서 내보내는 경우 데이터 플로우 안에서 대량의 데이터를 외부로 전송하는 것은 피하는 편이 무난
- 벌크 형의 전송 도구를 사용하여 태스크 구현 하거나, 외부 시스템 쪽에서 파일을 읽어 들이조록 지시
<데이터 플로우와 SQL을 나누어 사용>
- SQL을 MPP 데이터 베이스에서 실행
- 데이터 웨어하우스의 파이프라인
- 분산 시스템상의 쿼리 엔진에서 SQL 실행
- 데이터마트의 파이프라인
- 대화식 플로우
- 애드 록 분석에서는 많은 데이터 처리를 수작업으로 시행하므로 워크플로 필요 x
- 구조화 되지 않은 데이터를 애드 혹 분석시 데이터 플로우가 유용
- 대화식 플로우
- 애드 록 분석에서는 많은 데이터 처리를 수작업으로 시행하므로 워크플로 필요 x
- 구조화 되지 않은 데이터를 애드 혹 분석시 데이터 플로우가 유용
300x250
반응형
'Data Engineering > 책정리' 카테고리의 다른 글
| [빅데이터를 지탱하는 기술] Ch4.빅데이터의 축적 (0) | 2023.04.02 |
|---|---|
| [빅데이터를 지탱하는 기술] Ch3.빅데이터 분산 처리 프레임워크 (1) | 2023.03.12 |
| [빅데이터를 지탱하는 기술] Ch2.빅데이터 탐색 (0) | 2023.01.02 |
| [빅데이터를 지탱하는 기술] Ch1.빅데이터 기초 지식 (0) | 2023.01.01 |
| [빅데이터를 지탱하는 기술] Ch0 (0) | 2022.12.30 |