1.교차검증과 모델선택
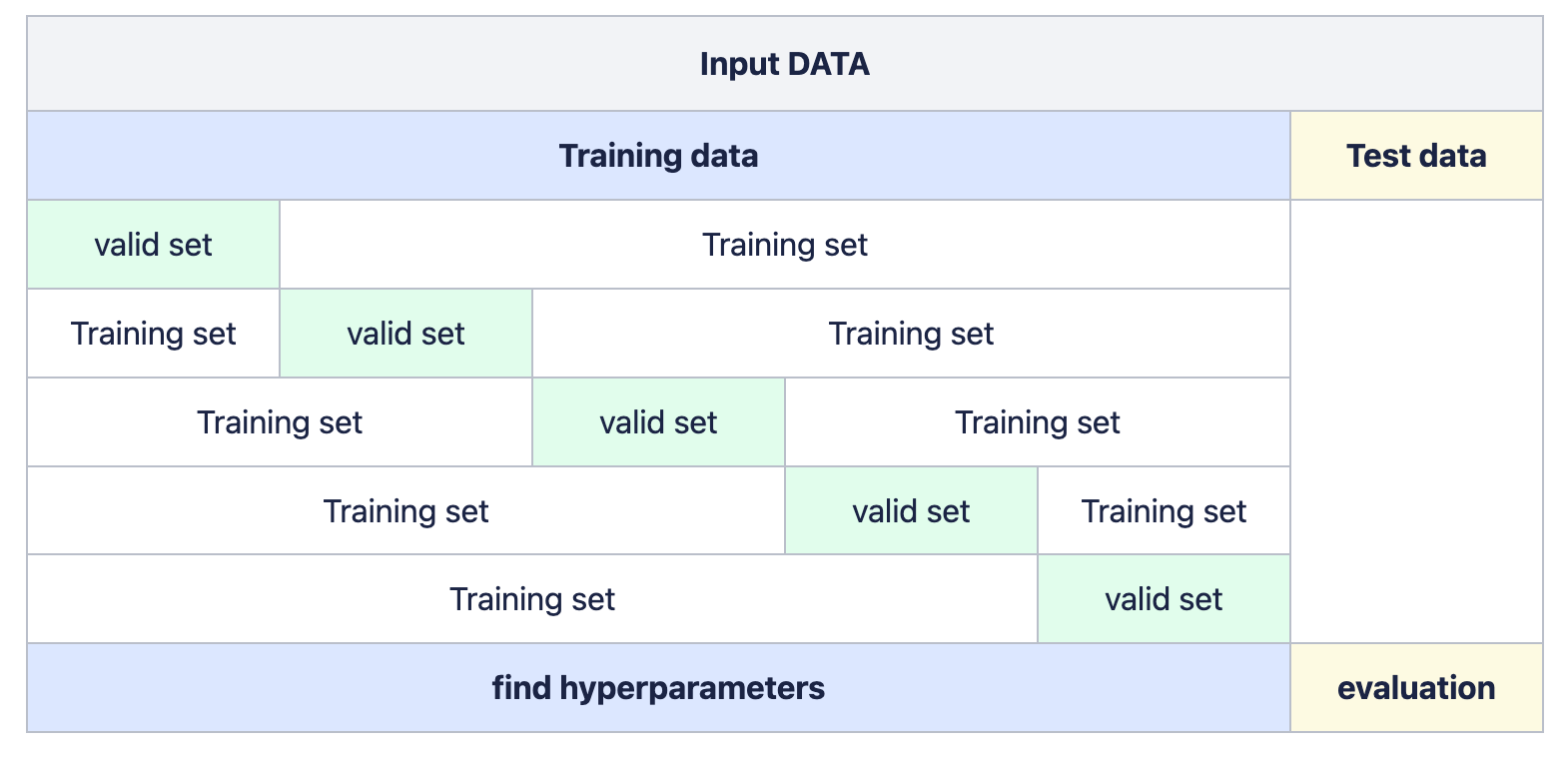
ML 알고리즘 마다 조절해야할 하이퍼 파라미터 옵션이 존재하는데 이를 조정하면서 학습데이터에서 과소적합, 과대적합을 방지 할 수 있다. 그 중 교차검증 방법론은 연속적으로 훈련과 검증 단계를 교차해가며 모델 성능을 검증하는데 여기서 주어진 데이터에서 최적의 하이퍼 파라미터를 보유한 가장 성능이 높은 모델을 선택한다.
- 장점
- 모든 데이터 셋을 평가, 훈련에 활용 → 과소적합, 과대적합 방지
- 모델 선택
- 단점
- 시간이 오래걸림
위의 사진에서 예시는 5폴드 교차검증으로 학습 데이터와 검증 데이터를 활용하여 검증시 가장 성능이 좋은 모델, 하이퍼 파라미터를 선택한 후 테스트 데이터를 활용하여 마지막 평가 진행.
- 로지스틱 파라미터 참고:https://runawayhorse001.github.io/LearningApacheSpark/reg.html
10. Regularization — Learning Apache Spark with Python documentation
10. Regularization In mathematics, statistics, and computer science, particularly in the fields of machine learning and inverse problems, regularization is a process of introducing additional information in order to solve an ill-posed problem or to prevent
runawayhorse001.github.io
# 모델선언
lr = LogisticRegression(labelCol = "Class", featuresCol = "features")
# 파라미터 그리드 지정
paramGrid = ParamGridBuilder().addGrid(lr.regParam, [0.0, 1.0])\
.addGrid(lr.elasticNetParam, [0.1, 0.25, 0.5, 0.75, 0.9])\
.build()
# metricName: areaUnderROC, areaUnderPR 2가지 지원
evaluator = BinaryClassificationEvaluator(labelCol = "Class", metricName = "areaUnderPR")
# 5폴드 교차검증
cv = CrossValidator(
estimator = lr,
estimatorParamMaps = paramGrid,
evaluator = evaluator,
numFolds = 5
)
# 모델학습 및 평가
model2 = cv.fit(train)
model_prediction2 = model2.transform(test)
# cv 결과 확인 - train에서 어떤 모델 선택 됐는지
import pandas as pd
params = [{p.name: v for p, v in m.items()} for m in model2.getEstimatorParamMaps()]
pd.DataFrame.from_dict([
{model2.getEvaluator().getMetricName(): metric, **ps}
for ps, metric in zip(params, model2.avgMetrics)
]).sort_values(by = "areaUnderPR", ascending = False)
300x250
반응형
'Data Science > 머신러닝' 카테고리의 다른 글
| [PySpark] 신용카드 사기거래 탐지 모델링(3) - 기본모델링 (0) | 2023.06.27 |
|---|---|
| [머신러닝] ROC 커브, PR 커브 모델 성능 평가시 무엇을 언제 쓸까? (0) | 2023.06.27 |
| 오버피팅(overfitting)과 언더피팅(underfitting)이 뭐길래? (0) | 2023.06.27 |
| [PySpark] 신용카드 사기거래 탐지 모델링(2) - 성능지표정의 (0) | 2023.06.22 |
| [PySpark] 신용카드 사기거래 탐지 모델링(1) - 데이터 탐색 (0) | 2023.06.21 |