
1-1 [배경] 빅데이터의 정착
<빅데이터 취급이 어려운 두 가지 이유>
- 데이터 분석 방법을 모르고 → 책에선 다루지 않음
- 데이터 처리에 수고와 시간이 걸림 → 알고 싶은 정보가 있다는 가정하 어떻게 효율적으로 처리할지
<빅데이터 기술 두 가지>
- Hadoop: 다수의 컴퓨터에서 대량의 데이터를 처리하기 위한 시스템
- 구글에서 개발된 MapReduce(분산 처리 시스템)를 참고하여 제작됨
- 초반 데이터 처리 위해 자바 언어로 프로그래밍 → 어려움, SQL쿼리 언어를 Hadoop에서 실행하기 위한 Hive(2009년) 출시
- 프로그래밍 없이 데이터 집계 가능, 분산 시스템의 간단화로 사용자 확대
- NoSQL: 전통적인 관계형 데이터 베이스(RDB) 제약 제거한 데이터 베이스
- 다양한 조합: ‘키 - 밸류 스토어(key-value store, KVS)’, ‘도큐먼트 스토어(document store)’, ‘d 와이드 칼럼 스토어(wide-column store)’
- RDB에 비해 고속의 읽기 , 쓰기, 분산처리에 뛰어남
- 모여진 데이터를 나중에 집계하는 Hadoop과 다르게 애플리케이션에서 온라인으로 접속하는 데이터 베이스
- Hadoop과 NoSQL 조합: NoSQL로 기록 Hadoop으로 분산 처리 → 현실적인 비용으로 데이터 처리
웹 서버에서 생성된 데이터 → RDB, NoSQL 등 데이터에 저장 → 하둡으로 모여 대규모 데이터 처리
<분산시스템의 비즈니스 이용 개척>
- 기존 데이터 웨어 하우스(data warehouse, DWH) → Hadoop, Hive 사용하는 경우 증가
- 왜? 대량의 데이터를 보존 및 집계, DWH에서도 빅데이터 처리 가능한데 왜?
- 일부 DWH 하드웨어, 소프트웨어 통합된 통합 장비로 제공, 용량 늘리려면 하드웨어 교체하는 등 쉽지 않음
- 늘어나는 데이터 처리는 확장성이 좋은 Hadoop에 맡기고 중요하거나 작은 데이터는 DWH에.
<클라우드 서비스로 빅데이터 활용 증가>
- 여러 컴퓨터로 분산처리 → 하드웨어 준비 어려움
- 클라우드 서비스, 시간 단위로 필요한 자원 확보
- 클라우드를 위한 Hadoop: Amazone Elastic Mapreduce, Azure HDInsight
- 데이터 웨어 하우스: 구글 BigQuery, Amazone Redshift
1-2 빅데이터 시대의 데이터 분석 기반
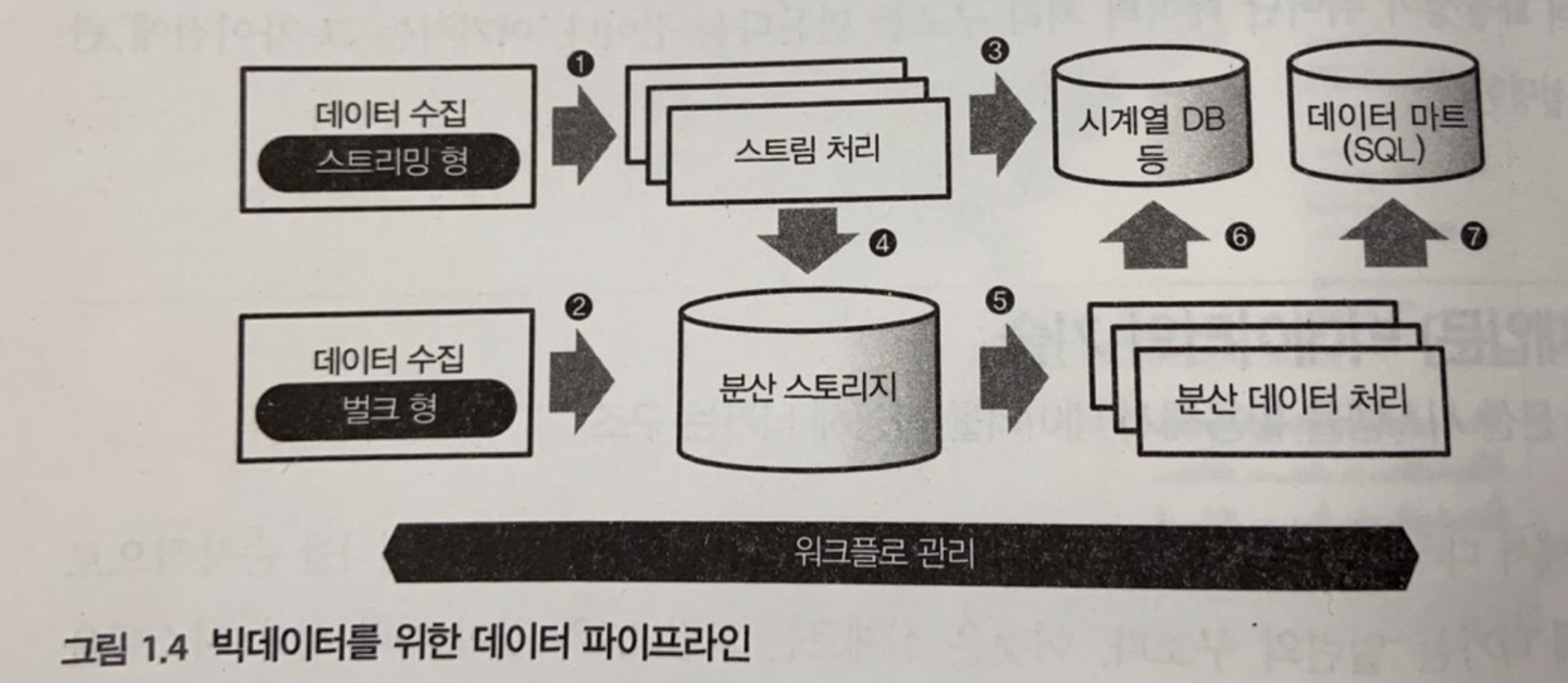
<빅데이터의 기술: 분산 시스템을 활용하여 데이터를 가공해가는 과정>
- 데이터 파이프라인: 데이터 수집에서 workflow 관리
- 데이터 수집: 벌크 형과 스트리밍 형의 데이터 전송
- 벌크(bulk) 형: 이미 어딘가에 존재하는 데이터를 정리해 추출, 데이터베이스와 파일 서버 등에서 정기적인 데이터 수집
- 스트리밍(streaming) 형: 차례 생성되는 데이터를 끊임없이 계속해서 보내는 방법, 모바일 애플리케이션, 임베디드 장비 등에서 널리 데이터를 수집
- 스트림 처리와 배치 처리
- 스트림 처리: 실시간 처리, 시계열 DB, 단기적인 데이터 분석에 적합
- 배치 처리: 대량의 데이터를 저장하고 처리, 어느정도 정리된 데이터를 효율적으로 가공
- 분산 스토리지: 수집된 데이터를 저장, 여러 컴퓨터와 디스크로 구성
- 객체 스토리지(object storage): 한 덩어리로 모인 데이터에 이름 부여해 파일로 저장, Amazone S3 등
- NoSQL: 애플리케이션에서 많은 데이터를 읽고 쓰려면 NoSQL이 성능 우수, 따라서 분산 스토리지로 사용, 나중에 데이터 용량을 늘리기 위해 확장성이 높은 제품 선택
- 분산 데이터 처리: SQL을 이용한 빅데이터 집계방식 쿼리 엔진, ETL 프로세스
- 분산 스토리지에 저장된 데이터 처리를 위해선 분산 데이터 처리(distribute data processing)의 프레임워크가 필요함.
- 나중에 분석하기 쉽도록 데이터 가공, 결과를 외부 DB에 저장
- 쿼리 엔진(query engine): 분산 스토리지 상의 데이터 집계, Hive, 대화형 쿼리 엔진(interactive query engine, Hive 보다 고속)도 개발
- ETL(extract - transform - load) 프로세스: 외부의 DWH 제품 이용, 분산 스토리지에서 데이터 추출, DWH에 적합한 형식으로, DWH에 로드(load)
- workflow 관리
- 매일 정해진 시간에 배치 처리 스케쥴 대로 실행, 오류 발생시 관리자에게 통지
- 오류 발생 시의 처리 기능 중요
<데이터 웨어하우스와 데이터 마트>
- DWH는 대량 데이터 장기 보존에 최적화, 소량의 데이터 자주 쓰고 읽는데 적합 X
- 데이터 소스(data source): 업무 시스템을 위한 RDB나 로그 등을 저장하는 파일 서버
- ETL 프로세스: 데이터 웨어하우스에 로우 데이터(raw data)를 추출하고 가공하여 저장
- 데이터 분석에 필요한 데이터를 웨어하우스에서 추출하여 데이터 마트(data mart) 구축
- 둘다 SQL로 집계
<데이터 레이크>
- 우선 데이터가 있고 나중에 테이블을 설계하는게 빅데이터
- 데이터의 축적 장소, 분산 스토리지가 데이터 레이크로 이용, 대부분 CSV, JSON 등 범용적인 텍스트 형식으로 저장
- 데이터 웨어하우스를 레이크로 치환 → 미가공 원시 데이터를 그대로 저장소에 저장
- 단순한 스토리지, 데이터 가공 X, MapReduce 등의 분산 데이터 처리 기술을 이용해 데이터 마트로 추출하여 분석 진행
<데이터 분석 기반을 단계적으로 발전: 팀과 역할 분담, 스몰 스타트와 확장>
- 데이터 엔지니어, 데이터 분석가
- 애드 혹 분석(ad hoc analysis): 일회성 데이터 분석, 수작업, 데이터 레이크 와 웨어하우스에 직접 연결하는 경우가 많음, 대화형 분석 도구 사용으로 즉시 결과 확인
- 대시보드 도구: 정기적인 그래프와 보고서
<데이터를 수집하는 목적: 검색, 가공, 시각화의 세가지 예>
- 데이터 검색: 언제 무엇이 필요할지 모름, 시스템 로그 및 고객의 행동 이력 등 발생하는 모든 데이터 취득, 필요할 때 신속하게 검색, 실시간 데이터 처리나 검색 엔진
- 데이터 가공: 필요한 데이터를 계획적으로 모아 파이프 라인 설계, 자동화 필수, 업무 시스템의 일부, 웹 사이트에 추천 상품 추천 비정상 데이터 감지 통보 등, 시스템 개발 영역
- 데이터 시각화: 상황 예측, 의사 결정에 도움
<확증적 데이터 분석과 탐색적 데이터 분석>
- 확증적 데이터 분석(confirmatory data analysis): 가설을 세우고 검증
- 통계학적 모델링에 의한 데이터 분석
- 탐색적 데이터 분석(exploratory data analysis): 데이터를 보며 의미 읽음
- 데이터 시각화, 사람의 힘으로 읽음
1-3 [속성 학습] 스크립트 언어에 의한 특별 분석과 데이터 프레임
<p28>
- 웹 로그 형태 파이썬 코드 참고용
- pandas: 빅데이터 처리 x
- 스몰데이터는 스몰데이터 기술을 사용하는 것이 효율적
1-4 BI 도구와 모니터링
<스프레드 시트에 의한 모니터링: 프로젝트 현재 상황 파악하기>
- 모니터링을 통해 계획적으로 데이터 변화 추적
- 데이터의 변화가 예상과 다르면 사람의 판단이 필요
- 현재 상황 파악 → 통찰 → 파악 및 판단
<데이터에 근거한 의사 결정: KPI 모니터링>
- 온라인 광고 KPI: CPR, CPC, CPA 등
- 데이터 기반(data driven) 의사 결정
- 목표와 실적 모니터링 위한 월간 보고서
<변화를 파악하고 세부 사항을 이해하기: BI 도구 활용>
- Tableau, Quick sencse, Microsoft power BI, 구글 Data studio
- 고속의 집계 엔진 내장, 스몰 데이터 그래프를 그려줌
- 정기적인 보고를 통해 변화 파악 → 원인이 되는 데이터를 재집계 하여 원인 파악
<수작업과 자동화해야 할 것의 경계를 판별>
- 자신이 알고 싶은 자신만 본다면 새로운 데이블을 설계부터 시작하기보다는 한 달에 한번 수작업으로 하지 배치 작업하고 테이블 설계까지 할 필요가 있을까 비효율적이게.
- 자동화 하는 경우 데이터 마트 구축부터
- 자주 업데이트 및 다른 사람과 공유되는 것은 차례로 자동화
- 데이터 마트를 준비해서 BI 도구로부터 연결 장) 자유럽게 만듦, 단) 마트 구축에 설치 운영 시간 듦.
300x250
반응형
'Data Engineering > 책정리' 카테고리의 다른 글
| [빅데이터를 지탱하는 기술] Ch5.빅데이터 파이프관리 (1) | 2023.05.07 |
|---|---|
| [빅데이터를 지탱하는 기술] Ch4.빅데이터의 축적 (0) | 2023.04.02 |
| [빅데이터를 지탱하는 기술] Ch3.빅데이터 분산 처리 프레임워크 (1) | 2023.03.12 |
| [빅데이터를 지탱하는 기술] Ch2.빅데이터 탐색 (0) | 2023.01.02 |
| [빅데이터를 지탱하는 기술] Ch0 (0) | 2022.12.30 |