
4-1 벌크 형과 스트리밍 형의 데이터 수집
<객체 스토리지와 데이터 수집>
- 빅데이터는 대부분 확장성이 높은 분산 스토리지(distributed storage)에 저장
- Hadoop 이라면 HDFS, 클라우드 서비스라면 Amazon S3
- 객체 스토리지(object storage)에서는 다수의 컴퓨터를 사용해 파일을 여러 디스크에 복사
- 데이터의 중복화 및 부하 분산
- 파일 읽고 쓰는데 네트워크 거쳐 실행
- 여러 디스크에 복사하기 때문에 일부 고장 나더라도 데이터 손실 x
- 다수의 하드웨어에 분산해 데이터 양 커도 성능 유지
- 소량에 데이터에서는 오히려 비효율적, 데이터양에 비해 통신 오버헤드가 큼
- 빅데이터에서 자주 다루는 것은 시계열 데이터
- 수시로 객체 스토리지에 기록시 대량의 작은 파일이 생성돼 성능 저하
- 적당히 모아서 하나의 큰 파일로 만드는게 효율적
- 객체 스토리지에서 효율적 처리의 파일 크기는 대략 1메가바이트 ~ 1기가바이트
- 그거보다 작으면 모아서 크게 만들고, 큰 데이터는 복수로 나눔
- 데이터 수집
- 수집한 데이터를 가공해 집계 효율이 좋은 분산 스토리지를 만드는 일련의 프로세스
- 데이터수집, 구조화 데이터 작성, 스토리지에 대한 장기적인 저장
<벌크 형의 데이터 전송>
- 원천 데이터가 분산 스토리지에 저장돼 있는게 아니라면 데이터 전송을 위한 ETL 서버 설치
- 구조화된 데이터 처리에 적합한 DW를 위한 ETL 도구
- 오픈소스의 벌크 전송 도구
- 작성 스크립트 등 이용
- 파일 사이즈 적정화
- 데이터 양 많을땐 작은 태스크로 분해
- 데이터 양 적을땐 모아서 전송
- 워크플로우 관리도구 활용
- 벌크 형 전송의 장점
- 데이터 신뢰성
- 실패시 재실행

<스트리밍 형 데이터 전송>
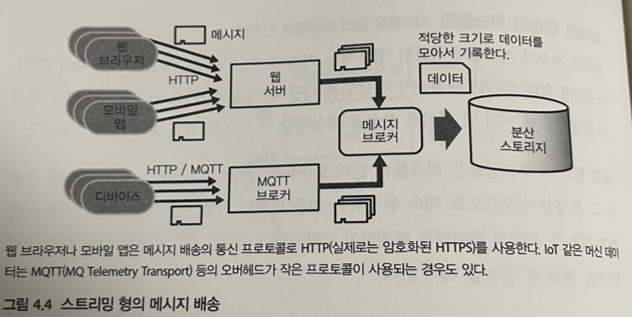
- 웹 브라우저, 모바일 앱, 센서 기기 등의 디바이스에서 수집
- 다수의 클라이언트에서 계속해서 작은 데이터 전송
- 메세지 배송(message delivery)
- 전송되는 데이터 양에 비해 통신을 위한 오버헤드가 커지기 때문에 이를 처리하는 높은 성능의 서버가 요구
- Hive와 같은 쿼리 엔진으로 NoSQL 데이터 베이스에 연결하여 사용
- 웹 브라우저에서의 메세지 배송
- 웹 서버안에서 메세지를 만들어 배송
- 전송 효율 측면 두가지 방법
- 서버상 데이터 축적후 모아서 보냄, Fluentd, Logstash 등과 같은 로그 수집기 이용
- 자바 스크립트를 사용하여 웹 브라우저에 직접 메시지를 보내는 경우, 웹 이벤트 추적(web event tracking), HTML 페이지에 태그 삽입하여 각종 액세스 분석 및 데이터 분석 서비스 등에 사용됨
- 모바일 앱으로부터 메시지 배송
- 통신 방법만 보면 HTTP 프로토콜을 사용하는 클라이언트로 메세지 배송 방식이 웹브라우저와 동일함
- 서버를 직접 마련하는 것이 아니라 MBaaS(Mobile Backend as a Service)라는 각종의 백엔드 서비스 이용해 백엔드 데이터 저장소에 저장
- 모바일 앱에 특화된 액세스 해석 서비스를 통해 이벤트 데이터 수집
- 개발 키트(SDK)를 사용해 메세지 보냄
- 발생한 이벤트는 SDK 내부에 축적되고 온라인 상태가 되었을 때 모아서 보냄
- 모바일 회선을 불안정 하기 때문에 데이터 중복에 대한 대책 필요
- 디바이스로부터의 메시지 배송
- MQTT(MQ Telemetry Transport), TCP/IP를 사용해 데이터 전송, 일반적으로 Pub/Sub 형 메시지 배송 구조를 지님
- 주로 채팅 시스템이나 메시징 앱, 푸시 알람 등의 시스템에서 사용
- 메시지 배송의 공통화
- 메시지 배송 방식은 어디에서 데이터 수집하느냐에 따라 전혀 다름
- 클라이언트, 메시지가 처음 생성되는 기기
- 프론트엔드(frontend), 메시지를 먼저 받는 서버
- 역할은 클라이언트와의 통신 프로토콜을 제대로 구현
- 데이터 보호를 위해 암호화, 사용자 인증 구현
- 성능을 위한 높은 확장성
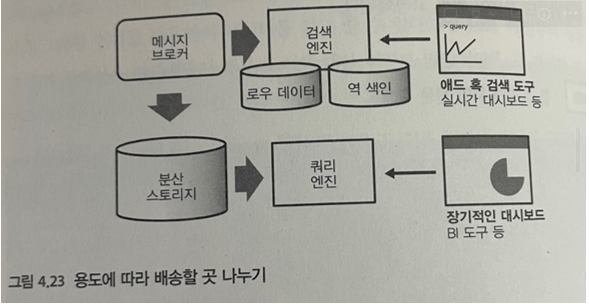
- 프론트엔드가 받은 메시지는 메시지 브로커로 전송
- 분산 스토리지에 데이터를 저장하는것은 메시지 브로커 이후의 역할
4-2 [성능*신뢰성] 메시지 배송의 트레이드 오프
<메시지 브로커>
- 쓰기의 빈도가 증가함에 따라 디스크 성능의 한계 도달
- 쓰기의 성능을 높이거나
- 클라이언트가 재전송 포기하고 부하가 떨어질 때까지 오류가 계속
- 대량의 메시지를 안정적으로 받기 위해서 데이터를 일시적으로 축적하는 중산층 설치 → 메시지 브로커
- 빅데이터를 위한 분산형 메시지 브로커
- 오픈소스 Apache Kafka
- Amazone Kinesis
- 푸쉬 형과 풀 형
- 푸쉬(push): 송신 측의 제어로 데이터를 보내는 방식
- 풀(pull): 수신 측의 주도로 데이터 가져옴
- 메시지 브로커는 데이터의 쓰기 속도를 조정하기 위한 완충 부분이며, 푸쉬 형에서 풀 형으로 메시지 배송 타이밍을 변환
- 생산자(producer): 메시지 브로커에 데이터를 push
- 소비자(consumer): 메시지 브로커에서 데이터를 pull
- 여러대의 노드에 부하 분산해 성능 최적화
- 푸쉬형 메시지 배송은 모두 메시지 브로커에 집중시키고 일정한 빈도로 꺼낸 데이터를 분산 스토리지에 기록

- 메시지 라우팅(message routing)
- 메시지 브로커에 써넣은 데이터는 복수의 다른 소비자에서 읽어 들일 수 있음
- 메시지 복사후 데이터를 여러 경로로 분기
<신뢰성의 문제와 세가지 설계 방식>
- 모바일 회선과 같이 신뢰성(reliability)가 낮은 네트워크에서는 메시지 중복, 누락 발생함
- 대부분 다음 세가지 중 하나를 보장
- at most once: 메시지 한 번만 전송, 결손 발생할 수 있음
- exactly once: 메시지는 손실되거나 중복 없이 한 번만 전달
- at least once: 메시지는 확실히 전달, 중복 발생할 수 있음
- at most once
- 재전송 시스템에서는 보장 어려움, 오류 감지해도 메시지가 보내지지 않았다라고 할 수 없기 때문
- exactly once
- 네트워크 상 분단된 두 개의 노드가 있는 경우 양쪽 통신 내용을 보장하려면 중계하는 코디네이터 존재가 필수적
- 문제 2가지
- 분산 시스템에 항상 코디네이터가 존재한다고 가정 x
- 코디네이터의 판단에만 따르면 시간 소요 많음
- at least once
- 메시지가 재전송 되어도 없앨 수 있는 구조만 있으면 보기에 중복이 없도록 중복제거(deduplication)
- 대부분 메시지 배송 시스템은 at least once를 보장하는 한편, 중복 제거는 이용자에게 맡김
- TCP/IP 처럼 자동으로 중복 제거 x
<중복 제거는 높은 비용의 오퍼레이션>
- 메시지 중복 제거하려면 같은 메시지를 과거에 받은 것인지 여부 판단 필요
- TCP에서는 시쿼스 번호 붙임
- 분산 시스템에서는 시퀀스 번호 사용 x → 성능 향상이 어려워 지기 때문
- 대안
- 오프셋을 이용한 중복제거
- 전송해야 할 데이터에 파일명 등의 이름을 부여해 작은 메시지에 실어 배송
- 파일 안의 시작위치(오프셋)을 덧 붙임
- 벌크 형 데이터 전송과 같이 데이터 양 고정인 경우 잘 작동
- 고유 ID에 의한 중복 제거
- 모든 메시지에 UUID(Universally Unique IDentifier) 등 고유 ID 지정
- 메시지 늘어나면 ID 폭발적으로 증가
- 관리가 필요
- 종단간(end to end)의 신뢰성
- 빅데이터 메시지 배송에서는 신뢰성 보다는 효율쪽이 중시
- 중간 경로에 at least once를 보장하는 한편 중복 제거는 하지 않는 것이 표준적인 구현
- 경로의 말단에서 중복 제거
- 고유 ID를 사용한 중복 제거 방법
- 분산 스토리지로 NoSQL DB 사용
- Cassandra, Elasticsearch, 특성상 데이터 쓸 때 고유 ID 지정
- SQL로 중복 제거
- 우선 객체 스토리지에 저장
- 읽는 단계에서 중복제거
- Hive와 같은 배치형 쿼리 엔진에서 실행
- 분산 스토리지로 NoSQL DB 사용
- 오프셋을 이용한 중복제거
4-3 시계열 데이터의 최적화
<프로세스 시간, 이벤트 시간>
- 이벤트 시간(event time): 클라이언트 상에서 메시지가 생성된 시간
- 프로세스 시간(process time): 서버가 처리하는 시간
<프로세스 시간에 의한 분할과 문제점>
- 분산 스토리지에 데이터를 넣는 단계에서는 이벤트 시간이 아니라 프로세스 시간을 사용하는 것이 보통
- 다수의 파일을 모두 검색하는 쿼리를 풀 스캔(full scan)
- 시스템 부하를 높이는 요인
- 불필요하게 전체 검사를 반복하는 것은 한정된 자원 낭비

<시계열 인덱스 - 이벤트 시간에 의한 집계 효율화1>
- 이벤트 시간에 대해 인덱스 만드는 것
- Cassandra와 같은 시계열 인덱스에 대응하는 분산 DB 이용
- 매우 짧은 범위의 특정 시간에 맞춘 데이터 집계 빠르게 실행
- 정해진 시간에 발생한 이벤트 조사, 실시간 대시보드 만드는데 유용
- 장기간에 걸쳐 대량의 데이터 집계하는 경우 분산 DB 비효율적
- 집계 효율이 높은 열 지향 스토리지를 지속적으로 만들어야 함
<조건절 푸쉬다운 - 이벤트 시간에 의한 집계 효율화2>
- 이벤트 시간으로 데이터 정렬 후 열 지향 스토리지로 변환
- 열지향 스토리지는 칼럼 단위의 통계 정보를 이용하여 최적화
- 예를들어, 최솟값, 최댓값 등이 모든 파일에 메타 정보로 저장
- 그 정보를 참고하여 어떤 파일의 어떤 부분에 원하는 데이터가 포함 돼 있는지 알 수 있음

<이벤트 시간에 의한 분할>
- 테이블 파티셔닝
- 파티션의 이름에 이벤트 발생시간 포함시킴, event_0101
- 이벤트 시간으로부터 시계열 데이터를 만들려면 작은 데이터를 효율적으로 추가할 수 있는 분산 DB를 사용하거나
- 너무 오래된 데이터는 버려야함
- 데이터 수집시 프로세스 시간 사용하고 데이터 마트를 만드는 단계에서 이벤트 시간에 의한 정렬도 방법
4-4 비구조화 데이터의 분산 스토리지
<[기본전략] NoSQL DB에 의한 데이터 활용>
- 빅데이터를 위한 분산 스토리지는 확장성과 유연성이 요구됨
- 기본이 되는 객체 스토리지
- 장점
- 임의의 파일을 저장할 수 있음
- 단점
- 스토리지 상 파일 교체 어려움 - 파일 통째 교체
- 로그파일처럼 변경할 일이 없는건 괜찮지만 DB처럼 수시로 변경은 적합 x
- 객체 스토리지에 저장된 데이터를 집계 하기 까지 시간이 걸림
- 장점
- 중요한 데이터는 트랜잭션 처리에 대해 고려된 DB에 저장하는게 원칙
- 특정 용도에 최적화된 데이터 저장소를 NoSQL DB라 불림
<NoSQL 예시>
- 분산 KVS
- 모든 데이터를 키값 쌍으로 저장하도록 설계된 데이터 저장소
- Amazon DynamoDB

- 와이드 칼럼 스토어
- 분산 KVS를 발전시켜 2개 이상의 임의의 키에 데이터 저장할 수 있도록 한 것
- Apache Cassandra, Google Cloud Bigtable, Apach HBase
- 행 키와 칼럼 명의 조합에 대해 값을 저장, 새로운 컬럼 얼마든지 추가 가능
- 성능향상 목표

- 도큐먼트 스토어
- 데이터 처리의 유연성이 목적
- Json처럼 복잡한 스키마 리스 데이터를 형태 그대로 저장, 쿼리 실행
- 장점은 스키마 정하지 않고 데이터 처리
- MongoDB
- 검색엔진
- NoSQL DB와 성격은 다르지만, 저장된 데이터를 쿼리로 찾아낸다는 점에서 유사함
- 텍스트 데이터 및 스키마리스 데이터를 집계하는데 사용
- 텍스트 데이터를 전문 검색하기 위해 역 색인을 만드는 부분, 데이터를 기록하는 시스템 부하 및 디스크 소비량은 크지만 키워드 검색이 고속화
- NoSQL DB는 성능 향상을 위해 색인 작성을 제한하지만 검색 엔진은 색인을 만들어 데이터 찾는것에 특화
- Elasticsearch, 로그 수집 소프트웨어 Logstash, 시각화 소프트웨어 Kibana와 함께 ELK 스택, Elastic 스택으로 자주 이용
- Splunk, 매일 발생하는 각종 이벤트를 빠르게 찾거나 보고서를 작성하는 목적으로 이용검색엔진
300x250
반응형
'Data Engineering > 책정리' 카테고리의 다른 글
| [빅데이터를 지탱하는 기술] Ch5.빅데이터 파이프관리 (1) | 2023.05.07 |
|---|---|
| [빅데이터를 지탱하는 기술] Ch3.빅데이터 분산 처리 프레임워크 (1) | 2023.03.12 |
| [빅데이터를 지탱하는 기술] Ch2.빅데이터 탐색 (0) | 2023.01.02 |
| [빅데이터를 지탱하는 기술] Ch1.빅데이터 기초 지식 (0) | 2023.01.01 |
| [빅데이터를 지탱하는 기술] Ch0 (0) | 2022.12.30 |