
2-1 크로스 집계의 기본
<트랜잭션 테이블, 크로스 테이블, 피벗 테이블>
- 크로스 테이블(cross table): 행, 열 교차 부분에 데이터
- 보기엔 편하지만 DB에서 다루긴 어려운 형식
- DB에서 행 추가는 간단, 열 추가는 어려움
- 트랜잭션 테이블(transaction table): 행 방향으로만 증가하는 테이블
- 크로스 집계(cross tabulation): 트랜잭션 테이블 → 크로스 테이블
- 소량의 데이터로 크로스 집계하는 건 구글 스프레드시트, 엑셀!!
- 소량 데이터 시각적으로 보기엔 엑셀 굳! 활용 많이 해보자

<룩업 테이블: 테이블을 결합하여 속성 늘리기>
- 룩업 테이블(lookup table): 참조 테이블
- 엑셀 vlookup으로 참조 테이블 구성, 트랜잭션 테이블과 독립적으로 구성
- 자주 데이터를 볼때는 엑셀보다 BI(Tableau 등) 사용하는게 좋다네 안 써봐서 모르겠지만
- 룩업 테이블이랑 트랜잭션 테이블 결합해서 보는듯
- pandas(merge → pivot_table, 대량 데이터 x), SQL(group by,대량 데이터 o)
- SQL 집계로 데이터 줄이고 → 크로스 집계(엑셀, BI 등)

<테이블 종횡 변환>
- SQL로 할 수 있긴 하지만 좀 비효율적
- 종 → 횡 가능, 횡 → 종 피곤 하여튼 비효율적임
- pandas 이용시 SQL보다는 괜츈 → pivot, melt 함수, 컬럼 많으면 메모리 부족
- 빅데이터에서는 SQL 집계 → 크로스 집계(엑셀, BI 등)이 괜츈할 듯
<데이터 집계 → 데이터 마트(크기에 따라 시스템 구성 결정) → 시각화>
- 데이터 마트 작으면 시각화 편리하지만 정보 잃어버림
- 많은 정보 집계하면 시각화 어려움
- 그래서? 집계 많을시 지연이 적은 적절한 DB사용 고려
2-2 열 지향 스토리지에 의한 고속화
<데이터베이스의 지연 줄이기>
- 데이터 처리 응답 시간이 빠르다, 대기 시간(latency)이 적다
- 데이터 마트 구축시 지연이 적은 DB 사용 → 두가지 선택지
- 1.간단하게 모든 데이터를 메모리에 올리기 → MySQL, PostgreSQL 등 일반적인 RDB 적합
- RDB는 지연이 적고 클라이언트 동시 접속해도 성능 낫베드
- 근데 메모리 부족시 성능 급격히 저하
- 로그 데이터 집계시 메모리 부족으로 터졌던 문제 있었음.
- 2.‘압축’과 ‘분산’에 의해 지연 줄이기 - MPP기술
- 데이터를 가능한 압축해 디스크에 분산, 데이터 로드에 따른 지연 줄임
- 분산된 데이터 읽을때 멀티 코어를 활용하고 디스트 I/O를 병렬처리 하는것이 효율적
- MPP(massive parallel processing, 대규모 병렬 처리)
- ex) Amazone Redshift, Google BigQuery
- DWH와 DM에서 데이터 집계에 최적화
- 클라우드 도입으로 진입장벽 낮아짐
<열 지향 DB vs 행 지향 DB>
- 행 지향 데이터베이스(row-orinted database): 각 행이 디스크 상 데이터로 기록
- ex) Oracle DB, MySQL
- 데이터 추가 효율적, 파일 끝에 데이터 씀, 대량의 트랜잭션 지연 없이 처리
- 데이터 검색 시 인덱스 사용
- 근데 데이터 분석시 어떤 컬럼 사용될지 모르니까 항상 디스크 I/O를 동반하며 인덱스가 도움이 안됨
- 열 지향 데이터베이스(column-oriented database): 컬럼 단위로 데이터 압축
- ex) Teradata, Amazone Redshift
- 필요한 칼럼만 로드하여 디스크 I/O를 줄임
- 데이터 압축 효율도 우수 → 같은 문자열 반복을 매우 작게 축소
<MPP 데이터베이스의 접근 방식: 병렬화, 멀티코어 활용>
- 행 지향 DB: 하나의 쿼리 하나의 스레드에서 실행, 많은 쿼리 동시에 실행하면 여러개 CPU 코어활용할 수 있지만 개별 쿼리가 분산 되는 것은 아님
- 열 지향 DB: 디스크에서 대량의 데이터 읽기 때문에 멀티 코어 활용
- 1억 레코드 합계 계산시 10만 레코드씩 1000개의 태스크로 나눔
- 각 태스크 10만개 합계 계산후 총합계 계산
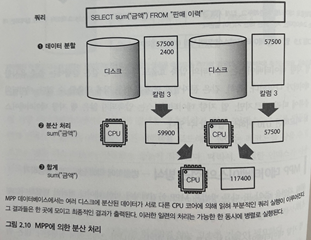
<MPP 데이터베이스와 대화형 쿼리 엔진>
- MPP 데이터베이스: 하드웨어 상에서 집계 최적화 데이터 베이스
- MPP 구조상 고속화를 위해 CPU, 디스크 균형 있게 늘려야 함 왜?
- MPP 사용 데이터 집계는 CPU 코어 수에 비례하여 가속화
- 근데 디스크에서 병목 현상 발생할 수도 있기 때문에 고르게 분산 돼야 함
- MPP 아키텍쳐는 Hadoop과 같이 사용되는 대화형 쿼리 엔진으로도 채택
- 근데 어쨌든 MPP 데이터베이스와 같은 성능 내려면 Hadoop 상에서도 데이터를 열 지향으로 압축하여 스토리지 구성 해야함

2-3 애드 혹 분석과 시각화 도구
<Jupyter Notebook 애드 혹 분석: 분석 과정 기록하기>
- 애드 혹 분석부터 시작
- matplotlib 활용해 시각화 까지
- 근데 csv로 저장해서 피벗 테이블 시각화 활용이 쉽긴 함 → 인사이트 도출시
- 수작업이 번거롭다면 → 자동화로 넘어가기
- 수작업이 간단하고 효율적인데 자동화 굳이???
- Json 파일이라 git 등으로 버전관리 쉬움 → 나중에 개인 프로젝트 할 때 해보기
<대시보드 도구: 정기적으로 집계 결과 시각화>
- 정해진 지표와 일상적인 변화 모니터링 시 대시보드 사용
- ex) Redash, Superset, Kibana(실시간)
- BI도구는 대화형 데이터 탐색, 시간 들여 차분히 데이터 보는 경우
- Redash: 파이썬으로 만든 도구, SQL 실행 결과를 시각화
- 데이터 소스 등록 → 쿼리 실행(표, 그림) → 그래프를 대시보드에 추가
- 등록한 쿼리 정기적으로 실행, 결과 내 DB에 저장
- 그래프의 수만큼 쿼리 실행
- 단: 대량 데이터 처리 X
<BI 도구: 대화적인 대시보드>
- 장기적인 데이터 추세 시각화, 세부적인 조건 집계
- 데이터 마트에 테이블을 만들고 다수의 대시보드 파생
2-4 데이터 마트의 기본 구조
<시각화에 적합한 데이터 마트 만들기: OLAP>
- OLAP(online analytical processing): 데이터 집계를 효율화하는 집계 방법
- 다차원 모델의 데이터 구조를 MDX(multidimensional expressions) 등의 쿼리 언어로 집계
- OLAP 큐브를 크로스 집계하는 구조
- BI도구와 MPP 데이터베이스 조합 하여 크로스 집계
- BI 도구를 위한 비정규화 테이블 만드는 프로세스
<테이블 비정규화하기>
- 트랜잭션(transaction): 시간과 함께 생성되는 데이터 기록, 한번 기록시 변화x
- 팩트 테이블(fact table): DWH에서 사실이 기록된 것, 판매액
- 마스터(master): 트랜잭션에 참고되는 각종 정보, 상황에 따라 다시 사용
- 디멘전 테이블(dimension table): 팩트 테이블 참고용, 속성값

- 스타 스키마
- 팩트 테이블 중심으로 여러 디멘전 테이블 결합
- 단순해서 이해하기 쉽고, 데이터 분석 용이
- 팩트 테이블에는 key값만 두어 성능 효율화
- 근데 요새는 MPP DB와 같이 열 지향 스토리지 도입으로 하나의 거대한 팩트 테이블(모든 테이블을 결합한 비정규화 테이블)만 있어도 됨 → 단순하고 충분히 효율적임
- 그러니까 데이터 메모리에 비해 많으면 열 지향 스토리지 쓰는게 굳
- DWH의 구조로는 스타 스키마가 좋음
- 데이터 축적 단계에서 팩트, 디맨전 테이블로 분리하고
- 분석(데이터 마트 만드는) 단계에 결합해 비정규화 테이블 만들기
<다차원 모델 시각화에 대비하여 테이블 추상화>
- 다차원 모델 칼럼 디멘전(dimension)과 측정값(measure)로 분류
- 디멘젼: 크로스 집계에 행과 열 이용
- 측정값: 숫자 데이터와 집계 방법 정의

<모델의 정의 확장>
- 시각화 하고자 하는 측정값과 디멘젼 결정
- 월별 상품의 매출: 금액(측정값), 판매일 및 상품명(디멘젼)
- 데이터 마트에 비정규화 테이블을 만들고 시각화
- 상품별 그룹으로 시각화 하고싶으면 제품 그룹이라는 새로운 디멘젼 추가 및 시각화
- 이런 비정규화 테이블 모은 것이 BI 도구를 위한 데이터 마트
- 비정규화 테이블 업데이트 하면 모든 그래프 업데이트
- 정규잡을 이용해 데이터 마트 업데이트하면 데이터 추이 확인 가능함
300x250
반응형
'Data Engineering > 책정리' 카테고리의 다른 글
| [빅데이터를 지탱하는 기술] Ch5.빅데이터 파이프관리 (1) | 2023.05.07 |
|---|---|
| [빅데이터를 지탱하는 기술] Ch4.빅데이터의 축적 (0) | 2023.04.02 |
| [빅데이터를 지탱하는 기술] Ch3.빅데이터 분산 처리 프레임워크 (1) | 2023.03.12 |
| [빅데이터를 지탱하는 기술] Ch1.빅데이터 기초 지식 (0) | 2023.01.01 |
| [빅데이터를 지탱하는 기술] Ch0 (0) | 2022.12.30 |