1.Random Forest
- 알고리즘
여러 개의 의사결정나무(Decision Tree) 모델을 배깅(bagging) 앙상블한 모델
bagging : training data로부터 랜덤하게 추출하여 동일한 사이즈의 데이터셋을 여러개 만들어 독립적인 트리를 구성
각 트리마다 변수들이 랜덤하게 사용(subsampling) > 개별 트리들의 상관성을 줄여 일반화 성능 확보
- 장점
일반화 및 성능 우수
파라미터 조정 쉬움
데이터 scaling 불필요
- 단점
샘플을 계속 추출하다 보면 비슷한 데이터가 만들어질 확률이 증가
해석이 어려움(앙상블 모형의 특징)
변수가 너무 적은 경우 랜덤성이 부족하여 성능 떨어짐
훈련시 메모리 소모 큼

2.XGBoost
- 알고리즘
여러 개의 의사결정나무(Decision Tree) 모델을 부스팅(boosting) 앙상블한 모델
Boosting : 이전 모형의 잔차(negative gradient)를 줄이는 방향으로 학습
병렬처리 지원으로 Gradient Boosting Machine(GBM) 보다 빠른 처리속도
Split Finding Algorithm : 가장 좋은 Split Point를 찾기 위해 가능한 모든 Split Point를 나열
- 장점
데이터 scaling 불필요
결측값이 없어도 학습 가능
- 단점
희소 데이터, non-tabular 데이터에서는 성능이 떨어짐
이상치에 민감
해석이 어려움(앙상블 모형의 특징)

3.LightGBM
- 알고리즘
여러 개의 의사결정나무(DecisionTree) 모델을 부스팅(boosting) 앙상블한 모델
GOSS(Gradient based One Side Sampling) : 잔차가 큰 관측값(모델이 충분히 학습하지 못한 관측값)에 초점을 맞추어 데이터의 크기를 줄임
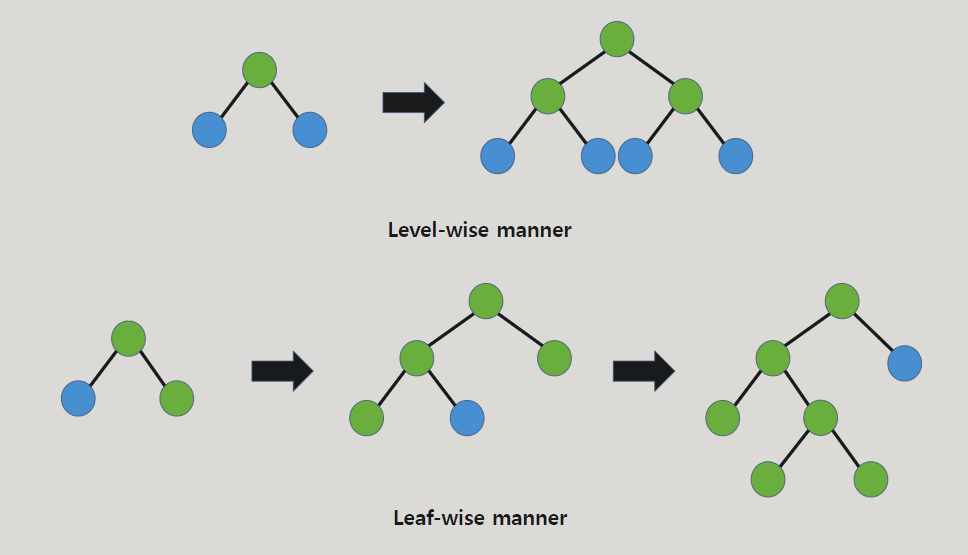
학습방법에서 트리 생성시 Leaf-wise 방법으로 트리 만듦 -> 학습 속도 빠름
ex) 일반적인 Decision Tree는 한 층에서 가지를 만들면 그 후 다른 층에서 가지를 만듦(Level-wise), LightGBM은 층에 대한 제약 없이 잎에서 가지를 침(Leaf-wise)
- 장점
적은 메모리 사용
데이터 scaling 불필요
병렬처리 지원으로 빠른 속도의 학습
- 단점
데이터 수가 적을때 과적합 가능성 높아 XGBoost 모델에 비해 성능 떨어짐
해석이 어려움(앙상블 모형의 특징)
- 알고리즘 특징 비교
| 장점 | 단점 | |
| Random Forest | 튜닝 파라미터 개수 적음 일반화 성능 높음 |
메모리 소모 큼 훈련 속도 오래 걸림 변수가 너무 적은 경우 랜덤성이 부족하여 성능 떨어짐 |
| Xgboost | 병렬 처리 효율적 | 희소 데이터, non-tabular 데이터에서는 성능이 떨어짐 이상치에 민감함 |
| LightGBM | 가장 빠른 훈련 속도 | 데이터가 적을 때 과적합 가능성 높음 |
'Data Science > 머신러닝' 카테고리의 다른 글
| [PySpark] 신용카드 사기거래 탐지 모델링(2) - 성능지표정의 (0) | 2023.06.22 |
|---|---|
| [PySpark] 신용카드 사기거래 탐지 모델링(1) - 데이터 탐색 (0) | 2023.06.21 |
| [머신러닝] 분류모델 성능지표 - 혼동행렬, AUC-ROC 커브, Lift/gain 차트 (1) | 2023.03.09 |
| [머신러닝] Kernel/Kernel trick(커널, 커널트릭) (0) | 2022.12.23 |
| [머신러닝]Support Vector Machine(SVM)에 대해 알아보자 (0) | 2022.11.27 |