[분류 모델 성능지표]
- 목적: 라벨이 있는 경우 이진 분류 모델의 성능지표에 대해 정리한다.
- 1.혼동행렬(confusion matrix),
- 2.AUC-ROC curve
- 3.lift chart, gain chart
1. 혼동행렬(confusion matrix)
| predicted | |||
| Positive | Negative | ||
| True | Positive | TP(True Positive) | FN(False Negative) |
| Negative | FP(False Positive) | TN(True Negative) | |
- TP: 양성인데, 양성으로 제대로 예측
- FN: 양성인데, 음성으로 잘못 예측
- FP: 음성인데, 양성으로 잘못 예측
- TN: 음성인데, 음성으로 잘못 예측
1-1.정확도(Accuracy)
ACC = (TP + FN) / (TP + FN + FP + TN)
전체 데이터 중에서 제대로 분류된 데이터의 비율, 모델이 얼마나 정확하게 분류하는지를 나타냄
1-2.오분류율(Error rate)
ERR = 1 - (TP + TN) / (TP + FN + FP + TN) = (FN + FP) / (TP + FN + FP + TN)
정확도의 반대로 전체 데이터 중에서 잘못 분류한 비율
1-3.민감도(Sensitivity, Recall)
SN = TP / (TP + FN)
실제 양성인 데이터에서 양성으로 예측한 비율, 모델이 얼마나 양성인 데이터를 잘 찾느냐를 나타냄
1-4.정밀도(Precision)
PREC = TP / (TP + FP)
예측한 양성인 데이터 중에서 실제 양성인 데이터의 비율
1-5.F1 score
F1 score = (2 * precision * recall) / (precision + recall)
정밀도와 민감도의 조화 평균, 값의 왜곡 현상을 방지
1-6.False Positive Rate(FPR)
FPR = FP / (FP + TN)
원래는 음성인 데이터인데 잘못해서 양성으로 예측한 비율, FPR이 높으면 정상을 비정상으로 판단하는 경우임
1-7.True Negative Rate(TNR, Specificity, 특이도)
SP = TN / (FP + TN)
실제 음성인 데이터 중에서 음성으로 예측한 데이터 비율
2. AUC-ROC 커브
AUC-ROC 곡선은 다양한 임계값에서 분류모델의 성능을 그래프로 표현한 것
2-1.ROC(Receiver Operating Characteristic)

ROC 커브는 FPR(False Positive Rate)와 TPR(True Positive Rate) 사이의 관계를 보여주는 곡선임. 여기서 FPR은 실제로 음성인 데이터 중에서 잘못 양성으로 예측한 비율이로 1 - 특이도(Specificity) 이고, TPR은 실제로 양성인 데이터를 올바르게 양성으로 예측한 비율로 민감도(Recall)이다.
이 커브는 각각의 분류 기준값(threshold)에서 FPR 과 TPR을 계산해서 그려지며, 왼쪽 위 모서리에 가까울수록 좋은 모델의 성능을 보인다.
2-2.AUC(Area Under the Curve)
AUC 커브는 ROC 커브 아래의 면적을 나타내는 값으로, 분류 모델의 전반적인 성능을 요약한다. 0 ~ 1 사이 값으로 ROC 커브를 수치적으로 요약한다. 1에 가까울수록 모델의 좋은 성능을 나타내고 0.5 이하라면 모델이 랜덤한 예측을 하는것과 같은 수준의 성능을 보인다고 판단 할 수 있다.
3.이익도표 - Gain 차트, Lift 차트
Lift 차트 와 Gain 차트는 라벨 불균형(Label Imbalanced) 데이터의 분류문제에서 성능을 측정하는 지표이다. 마케팅 분야에서 고객 세그먼테이션, 마케팅 캠페인 분석 등에서 유용하게 활용되며 예측 결과와 실제 결과를 비교하여 성능을 측정할 수 있다. 로지스틱 회귀 분석에서 모형을 사용할 때의 이점을 이해하는 데 도움이 되는 측도임.
예를들어, 대출 광고 캠페인을 진행했을 때 그 광고를 클릭하는 사람은 극소수임
Lift 차트와 Gain 차트의 차이점은 선택된 고객 집단의 크기임. Gain 차트는 고객을 일정한 수로 선택했을 때 모델이 얼마나 잘 예측하는지를 보여주는 반면에 Lift 차트는 고객을 일정 비율로 선택했을 때 모델이 얼마나 잘 예측하는지를 보여줌.
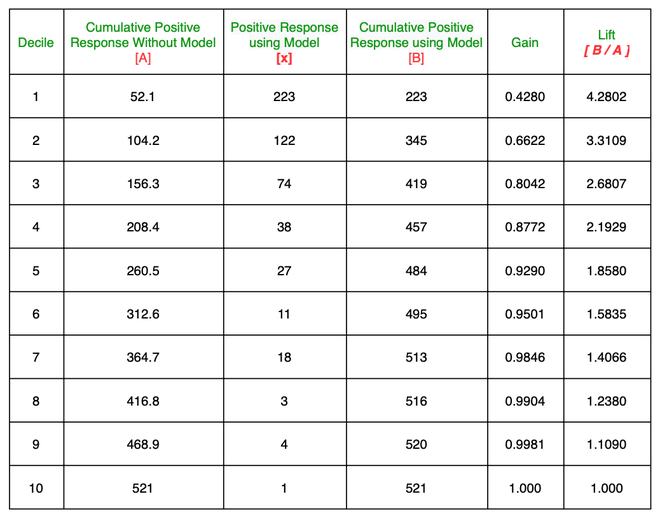
- 우선, 각 관측치에 대한 예측확률을 내림차순으로 정렬하고
- 데이터를 10개의 구간으로 나눈 다음 각 구간의 반응검출율(Captured Response) 반응률(Reponse)를 산출한다.
- 반응검출율(Catured Response): 해당 등급에서 실제 광고 클릭자 / 전체 광고 클릭자
- 반응률(Response): 해당 등급에서 실제 광고 클릭자 / 해당 등급의 인원
- 기본향상도(Baseline Lift): 전체 광고 클릭자 / 전체 대상
- 향상도(Lift): 반응률 / 기본향상도
- 기본향상도(Baseline lift)에 비해 반응률이 몇 배나 높은지를 계산하는데 이게 Lift(향상도)
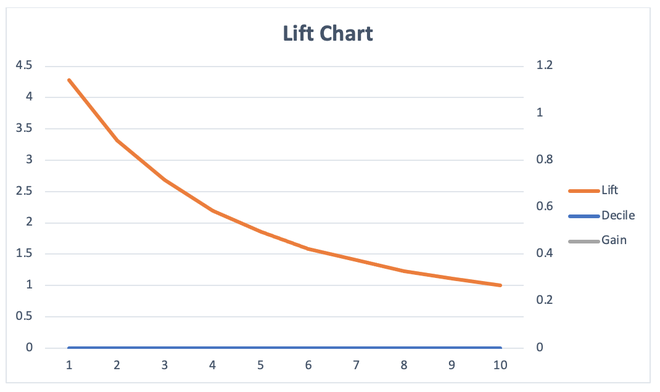
좋은 모델이라면 Lift가 빠른 속도로 감소해야 한다. → 상위 등급에서 최대한 많이 참값을 걸러내는 모형이 좋은 모형임
3-1.Gain 차트
고객을 선택할 때 모델이 얼마나 잘 예측하는지를 보여주는 그래프이다. 고객을 일정한 수로 선택했을때 모델이 얼마나 잘 예측하는지를 보여준다.

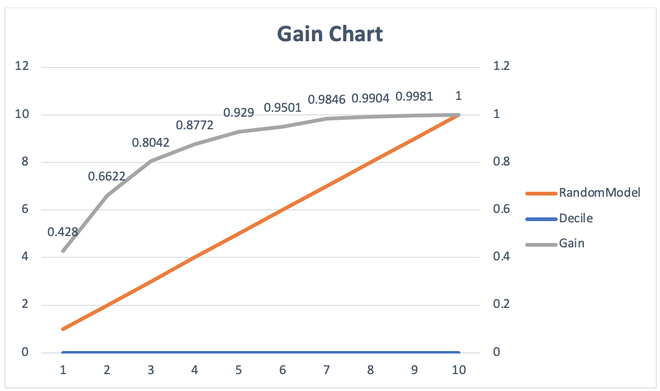
가로축은 고객 집단의 크기이고 세로축은 예측 대상을 찾아내는 비율임.
주황색 선은 무작위 선택의 예측 성능을 나타내는 선이고 회색선이 모델의 예측 성능을 나타냄. 두 선 사이의 거리가 멀수록 모델의 예측 성능이 높다는 의미임.
3-2.Lift 차트
누적 이득곡선(cumulative gain curve)과 비슷한 개념을 가지고 있다. 이득곡선은 고객 중에서 예측 대상을 찾아낼 확률이 높은 일부 고객을 선택했을 때, 해당 고객 집단에서 예측 대상의 비율이 얼마나 높은지를 나타내는 그래프임. 그러나 Lift 차트는 이득곡선에 좀 더 세부적인 정보를 추가하여 고객 선택 비율에 따른 예측 성능 변화를 나타낸다.
300x250
반응형
'Data Science > 머신러닝' 카테고리의 다른 글
| [PySpark] 신용카드 사기거래 탐지 모델링(2) - 성능지표정의 (0) | 2023.06.22 |
|---|---|
| [PySpark] 신용카드 사기거래 탐지 모델링(1) - 데이터 탐색 (0) | 2023.06.21 |
| [머신러닝] Random Forest, XGBoost, LightGBM 비교 (1) | 2023.01.03 |
| [머신러닝] Kernel/Kernel trick(커널, 커널트릭) (0) | 2022.12.23 |
| [머신러닝]Support Vector Machine(SVM)에 대해 알아보자 (0) | 2022.11.27 |