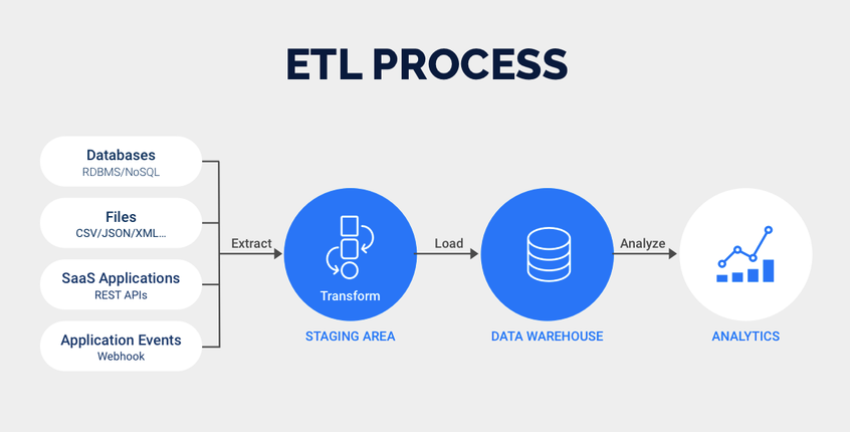
0.질문 reviewAB test모델 테스트시 처음에는 작게 시작, 1% 사용자에 대해별문제 없으면 5%, 10% 점차적으로 늘려감시리즈D 정도받고, 팀안정화 시 50:50 정도 가능하지 않나Airflow 알아야 할 부분시간이 지날수록 DAG가 점점 많아지기 때문에 정해진 시간에 시행되는 cronjob으로는 한계가 있음Backfill특정 DAG가 끝나면 다음 DAG, DAG들간의 dependency가 생김시간순으로 트리거 가능(세가지 방법)데이터 리니지 파악가능(어떤 데이터로부터 어떤 데이터가 생겨났는지), 데이터 과잉시 디스커버리 이슈, 데이터 카탈로그를 통해서 검색, 데이터 리니지 정보와 카탈로그 연동시 데이터 파악 쉽게 가능, 데이터 허브데이터 엔지니어 연봉이 높은이유수요가 큼학습이 많이 필요서포트..