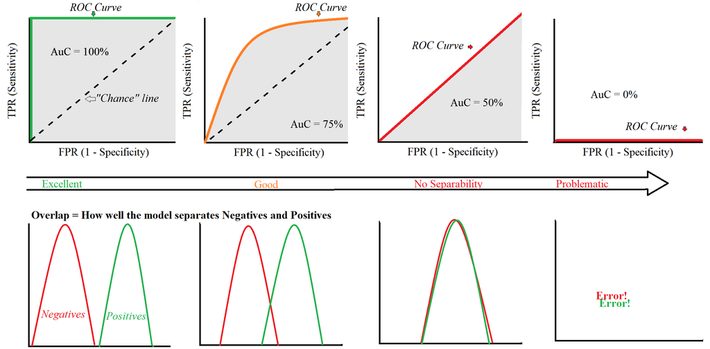
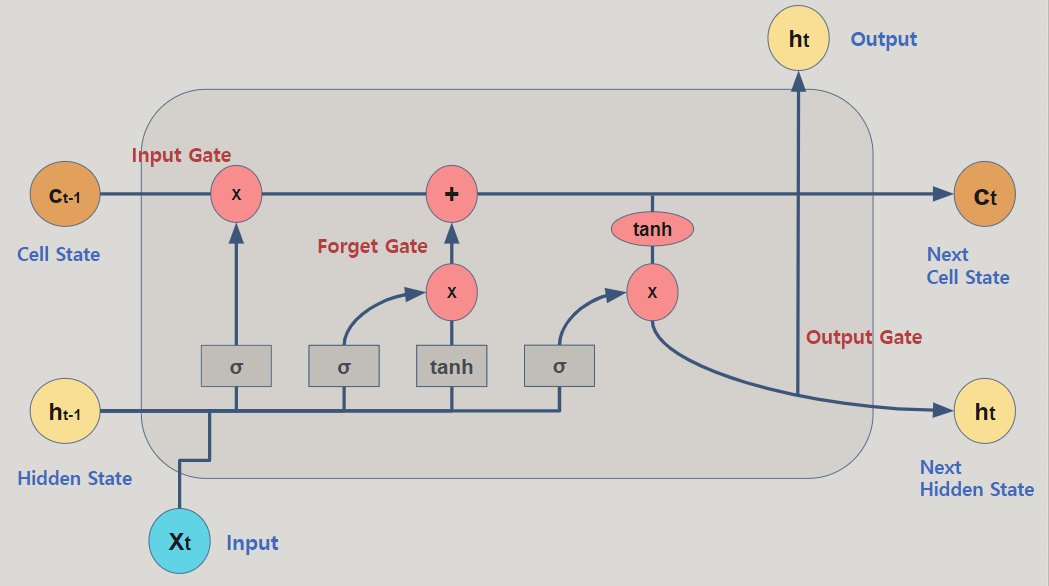
1.과소적합(underfitting)과 과대적합(overfitting) 모델이 데이터를 학습하는 과정에서 발생하는 과소적합, 과대적합 문제를 1) 모델 복합도 측면, 2) 데이터 정보량 측면에서 고려할 필요가 있음. 과소적합(underfitting): 학습 데이터조차 제대로 학습x(데이터 내재적인 구조 반영x), 편향이 높게(high bias) 학습되어 새로운 데이터를 예측하지 못하는 상태 과대적합(overfitting): 학습 데이터를 과하게 학습(지엽적인 특성까지 반영), 분산이 높게(high variance) 학습되어 새로운 데이터를 예측하지 못하는 상태 결론적으로, 편향을 높이면 학습이 잘 안되고, 편향이 낮으면 분산이 높아지는 절충(trade off) 관계로 두 가지 에러(error)를 최소화 ..