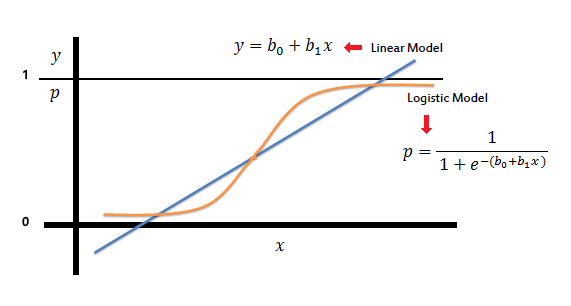
로지스틱 회귀 모형에서 범주형 변수인 Y(종속변수)를 예측하는데 기존의 X(독립변수)의 중요도(=기여도)를 파악한다면 데이터 정보 기반의 의사 결정을 내리고 모델 성능을 향상시키는데 필요한 과정이다. 이 게시물에서는 가중치를 사용하여 로지스틱 회귀에서 독립변수의 중요도를 얻는 방법에 대해 작성하고자 한다. 1.로지스틱 회귀모형(logistic regression model)? 로지스틱 회귀 분석은 이항 분류에 사용되는 통계적 방법이다. 즉, 일반적으로 0과 1로 표시된 두 가지 결과 중 하나를 예측하려는 경우에 일반적으로 적용되며. 로지스틱 회귀 분석은 일반적인 선형 회귀 알고리즘이 아닌 분류 알고리즘이다. 로지스틱 회귀 분석의 주요 아이디어는 주어진 입력이 특정 클래스에 속할 확률을 모델링하는 것이다...